
Écrire votre premier noyau GPU en Python avec Numba et Cuda
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 17 minutes de lecture
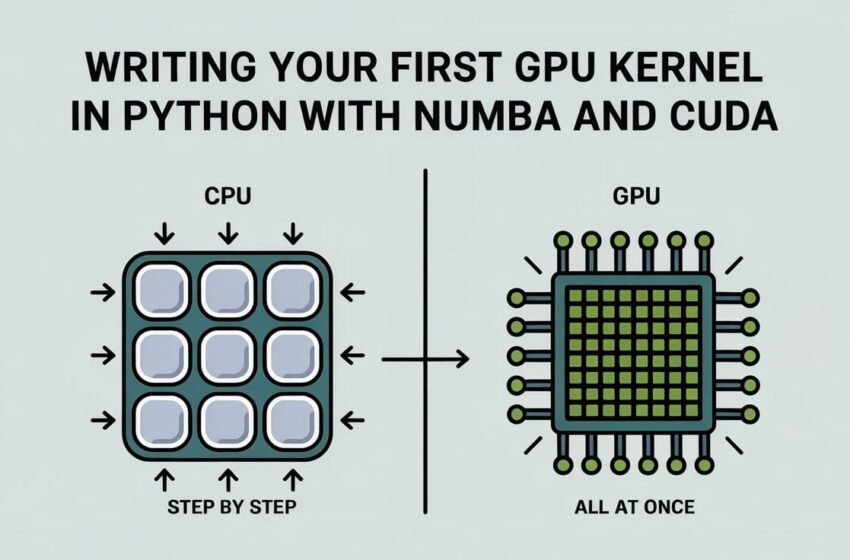
Image de l’auteur | Idéogramme
Les GPU sont parfaits pour les tâches où vous devez effectuer la même opération à travers différents éléments de données. Ceci est connu comme le Instruction unique, données multiples (SIMD) approche. Contrairement aux processeurs, qui n’ont que quelques noyaux puissants, les GPU ont des milliers de plus petits qui peuvent exécuter ces opérations répétitives à la fois. Vous verrez beaucoup ce modèle dans l’apprentissage automatique, par exemple lors de l’ajout ou de la multiplication de grands vecteurs, car chaque calcul est indépendant. Il s’agit du scénario idéal pour utiliser des GPU pour accélérer les tâches avec parallélisme.
Nvidia créé Cuda Afin pour les développeurs d’écrire des programmes qui s’exécutent sur le GPU au lieu du CPU. Il est basé sur C et vous permet d’écrire des fonctions spéciales appelées noyaux qui peuvent exécuter de nombreuses opérations en même temps. Le problème est que l’écriture de CUDA en C ou C ++ n’est pas exactement adaptée aux débutants. Vous devez gérer des choses comme l’allocation manuelle de la mémoire, la coordination des threads et la compréhension du fonctionnement du GPU à un niveau bas. Cela peut être écrasant, surtout si vous avez l’habitude d’écrire du code dans Python.
C’est là que Numba peut vous aider. Il permet d’écrire des noyaux Cuda avec Python en utilisant l’infrastructure de compilateur LLVM (machine virtuelle à bas niveau) pour compiler directement votre code Python en noyaux compatibles CUDA. Avec la compilation Just-in-Time (JIT), vous pouvez annoter vos fonctions avec un décorateur et Numba gère tout le reste pour vous.
Dans cet article, nous utiliserons un exemple commun d’ajout de vecteur et convertirons le code CPU simple en un noyau CUDA avec Numba. L’ajout de vecteur est un exemple idéal de parallélisme, car l’addition à travers un seul indice est indépendant des autres indices. Il s’agit du scénario SIMD parfait afin que tous les indices puissent être ajoutés simultanément pour compléter l’ajout de vecteur en une seule opération.
Notez que vous aurez besoin d’un GPU CUDA pour suivre cet article. Vous pouvez utiliser Colab GPU T4 gratuit ou GPU local avec NVIDIA Toolkit et NVCC installé.
# Configuration de l’environnement et installation Numba
Numba est disponible en tant que package Python, et vous pouvez l’installer avec PIP. De plus, nous utiliserons nombant pour les opérations vectorielles. Configurez l’environnement Python à l’aide des commandes suivantes:
python3 -m venv venv
source venv/bin/activate
pip install numba-cuda numpy# Ajout de vecteur sur le CPU
Prenons un exemple simple d’ajout de vecteur. Pour deux vecteurs donnés, nous ajoutons les valeurs correspondantes de chaque index pour obtenir la valeur finale. Nous utiliserons Numpy pour générer des vecteurs float32 aléatoires et générerons la sortie finale à l’aide d’une boucle pour une boucle.
import numpy as np
N = 10_000_000 # 10 million elements
a = np.random.rand(N).astype(np.float32)
b = np.random.rand(N).astype(np.float32)
c = np.zeros_like(a) # Output array
def vector_add_cpu(a, b, c):
"""Add two vectors on CPU"""
for i in range(len(a)):
c(i) = a(i) + b(i)Voici une ventilation du code:
- Initialiser deux vecteurs chacun avec 10 millions de nombres à virgule flottante aléatoires
- Nous créons également un vecteur vide
cPour stocker le résultat - Le
vector_add_cpuLa fonction boucle simplement via chaque index et ajoute les éléments deaetbstockant le résultat enc
C’est un opération en série; Chaque ajout se produit les uns après les autres. Bien que cela fonctionne bien, ce n’est pas l’approche la plus efficace, en particulier pour les grands ensembles de données. Étant donné que chaque ajout est indépendant des autres, il s’agit d’un candidat parfait pour l’exécution parallèle sur un GPU.
Dans la section suivante, vous verrez comment convertir cette même opération pour s’exécuter sur le GPU à l’aide de Numba. En distribuant chaque ajout par élément sur des milliers de threads GPU, nous pouvons effectuer la tâche beaucoup plus rapidement.
# Ajout de vecteur sur le GPU avec Numba
Vous utiliserez désormais Numba pour définir une fonction Python qui peut s’exécuter sur CUDA et l’exécuter dans Python. Nous effectuons la même opération d’addition de vecteur, mais maintenant il peut s’exécuter en parallèle pour chaque index du tableau Numpy, conduisant à une exécution plus rapide.
Voici le code pour écrire le noyau:
from numba import config
# Required for newer CUDA versions to enable linking tools.
# Prevents CUDA toolkit and NVCC version mismatches.
config.CUDA_ENABLE_PYNVJITLINK = 1
from numba import cuda, float32
@cuda.jit
def vector_add_gpu(a, b, c):
"""Add two vectors using CUDA kernel"""
# Thread ID in the current block
tx = cuda.threadIdx.x
# Block ID in the grid
bx = cuda.blockIdx.x
# Block width (number of threads per block)
bw = cuda.blockDim.x
# Calculate the unique thread position
position = tx + bx * bw
# Make sure we don't go out of bounds
if position < len(a):
c(position) = a(position) + b(position)
def gpu_add(a, b, c):
# Define the grid and block dimensions
threads_per_block = 256
blocks_per_grid = (N + threads_per_block - 1) // threads_per_block
# Copy data to the device
d_a = cuda.to_device(a)
d_b = cuda.to_device(b)
d_c = cuda.to_device(c)
# Launch the kernel
vector_add_gpu(blocks_per_grid, threads_per_block)(d_a, d_b, d_c)
# Copy the result back to the host
d_c.copy_to_host(c)
def time_gpu():
c_gpu = np.zeros_like(a)
gpu_add(a, b, c_gpu)
return c_gpuDécomposons ce qui se passe ci-dessus.
// Comprendre la fonction GPU
Le @cuda.jit Le décorateur dit à Numba de traiter la fonction suivante comme un noyau Cuda; Une fonction spéciale qui fonctionnera en parallèle sur de nombreux threads sur le GPU. Au moment de l’exécution, Numba compilera cette fonction avec du code compatible CUDA et gérera la transpilation C-API pour vous.
@cuda.jit
def vector_add_gpu(a, b, c):
...Cette fonction fonctionnera sur des milliers de threads en même temps. Mais nous avons besoin d’un moyen de déterminer la partie des données sur lesquelles chaque thread doit fonctionner. C’est ce que font les prochaines lignes:
txest l’ID du fil dans son blocbxest l’identifiant du bloc dans la grillebwest combien de fils il y a dans un bloc
Nous les combinons à Calculer une position uniquequi indique à chaque thread quel élément des tableaux qu’il doit ajouter. Notez que les threads et les blocs peuvent ne pas toujours fournir un indice valide, car ils fonctionnent dans des pouvoirs de 2. Cela peut entraîner des indices non valides lorsque la longueur du vecteur ne se conforme pas à l’architecture sous-jacente. Par conséquent, nous ajoutons une condition de garde pour valider l’index, avant d’effectuer l’ajout de vecteur. Cela empêche toute erreur d’exécution hors limite lors de l’accès au tableau.
Une fois que nous connaissons la position unique, nous pouvons maintenant ajouter les valeurs comme nous l’avons fait pour l’implémentation du CPU. La ligne suivante correspondra à l’implémentation du CPU:
c(position) = a(position) + b(position)// Lancement du noyau
Le gpu_add La fonction définit les choses:
- Il définit le nombre de threads et de blocs à utiliser. Vous pouvez expérimenter différentes valeurs de tailles de blocs et de threads et imprimer les valeurs correspondantes dans le noyau GPU. Cela peut vous aider à comprendre comment fonctionne l’indexation sous-jacente du GPU.
- Il copie les tableaux d’entrée (
a,betc) De la mémoire du CPU à la mémoire GPU, les vecteurs sont donc accessibles dans le GPU RAM. - Il exécute le noyau GPU avec
vector_add_gpu(blocks_per_grid, threads_per_block). - Enfin, il copie le résultat du GPU dans le
cArray, nous pouvons donc accéder aux valeurs du CPU.
# Comparaison des implémentations et de l’accélération potentielle
Maintenant que nous avons à la fois les versions CPU et GPU de Vector Addition, il est temps de voir comment ils se comparent. Il est important de vérifier les résultats et le boost d’exécution que nous pouvons obtenir avec le parallélisme CUDA.
import timeit
c_cpu = time_cpu()
c_gpu = time_gpu()
print("Results match:", np.allclose(c_cpu, c_gpu))
cpu_time = timeit.timeit("time_cpu()", globals=globals(), number=3) / 3
print(f"CPU implementation: {cpu_time:.6f} seconds")
gpu_time = timeit.timeit("time_gpu()", globals=globals(), number=3) / 3
print(f"GPU implementation: {gpu_time:.6f} seconds")
speedup = cpu_time / gpu_time
print(f"GPU speedup: {speedup:.2f}x")Tout d’abord, nous exécutons les deux implémentations et vérifions si leurs résultats correspondent. Ceci est important pour vous assurer que notre code GPU fonctionne correctement et que la sortie doit être la même que celle du processeur.
Ensuite, nous utilisons le Python intégré timeit Module pour mesurer la durée de chaque version. Nous exécutons chaque fonction plusieurs fois et prenons la moyenne pour obtenir un timing fiable. Enfin, nous calculons le nombre de fois plus rapidement que la version GPU est comparée au CPU. Vous devriez voir une grande différence car le GPU peut faire de nombreuses opérations à la fois, tandis que le processeur les gère un à la fois en boucle.
Voici la sortie attendue sur le GPU T4 de Nvidia sur Colab. Notez que la vitesse exacte peut différer en fonction des versions CUDA et du matériel sous-jacent.
Results match: True
CPU implementation: 4.033822 seconds
GPU implementation: 0.047736 seconds
GPU speedup: 84.50xCe test simple aide à démontrer la puissance de l’accélération du GPU et pourquoi elle est si utile pour les tâches impliquant de grandes quantités de données et des travaux parallèles.
# Emballage
Et c’est tout. Vous avez maintenant écrit votre premier noyau Cuda avec Numba, sans réellement écrire de code C ou CUDA. Numba permet une interface simple pour utiliser le GPU via Python, et il est beaucoup plus simple pour les ingénieurs Python de commencer avec la programmation CUDA.
Vous pouvez désormais utiliser le même modèle pour écrire des algorithmes CUDA avancés, qui sont répandus dans l’apprentissage automatique et l’apprentissage en profondeur. Si vous trouvez un problème après le paradigme SIMD, c’est toujours une bonne idée d’utiliser GPU pour améliorer l’exécution.
Le code complet est disponible sur Colab Notebook auquel vous pouvez accéder ici. N’hésitez pas à le tester et à apporter des changements simples pour mieux comprendre comment l’indexation et l’exécution de CUDA fonctionnent en interne.
Kanwal Mehreen est un ingénieur d’apprentissage automatique et un écrivain technique avec une profonde passion pour la science des données et l’intersection de l’IA avec la médecine. Elle a co-écrit l’ebook « Maximiser la productivité avec Chatgpt ». En tant que Google Generation Scholar 2022 pour APAC, elle défend la diversité et l’excellence académique. Elle est également reconnue comme une diversité de Teradata dans Tech Scholar, le boursier de recherche Mitacs Globalink et le savant de Harvard WECODE. Kanwal est un ardent défenseur du changement, après avoir fondé des femmes pour autonomiser les femmes dans les champs STEM.



