
Ingénierie des fonctionnalités alimentées par AI avec N8N: Échelle de la science des données
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 21 minutes de lecture

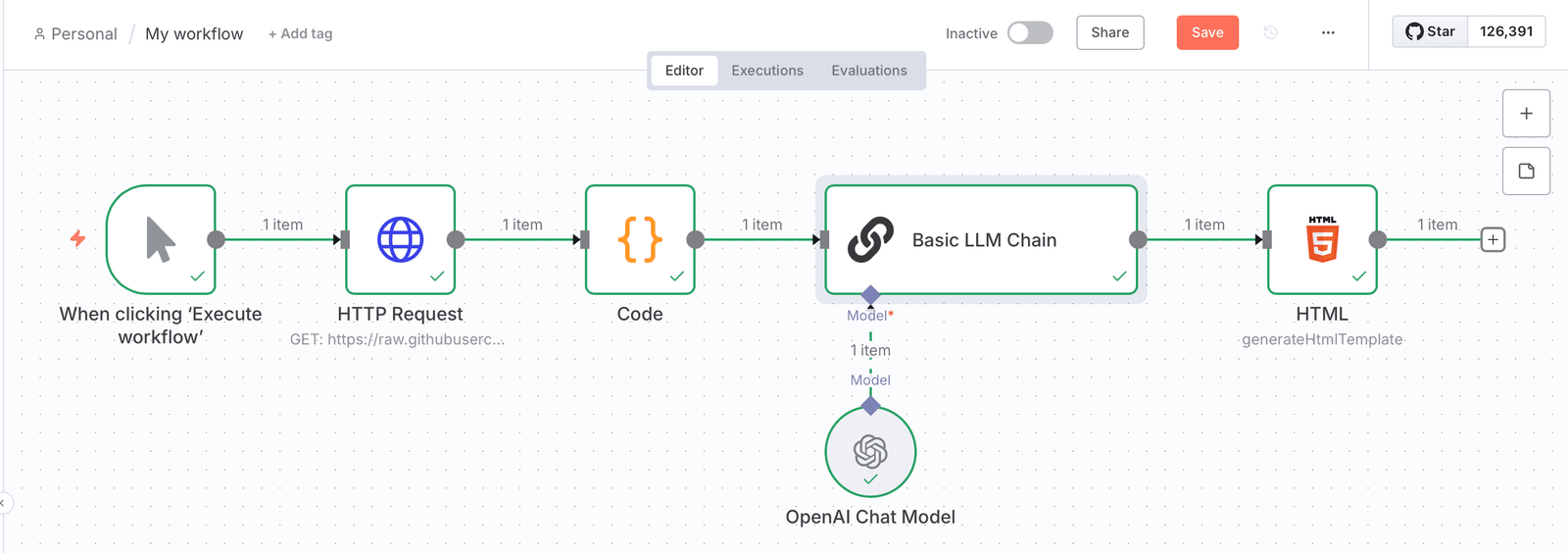
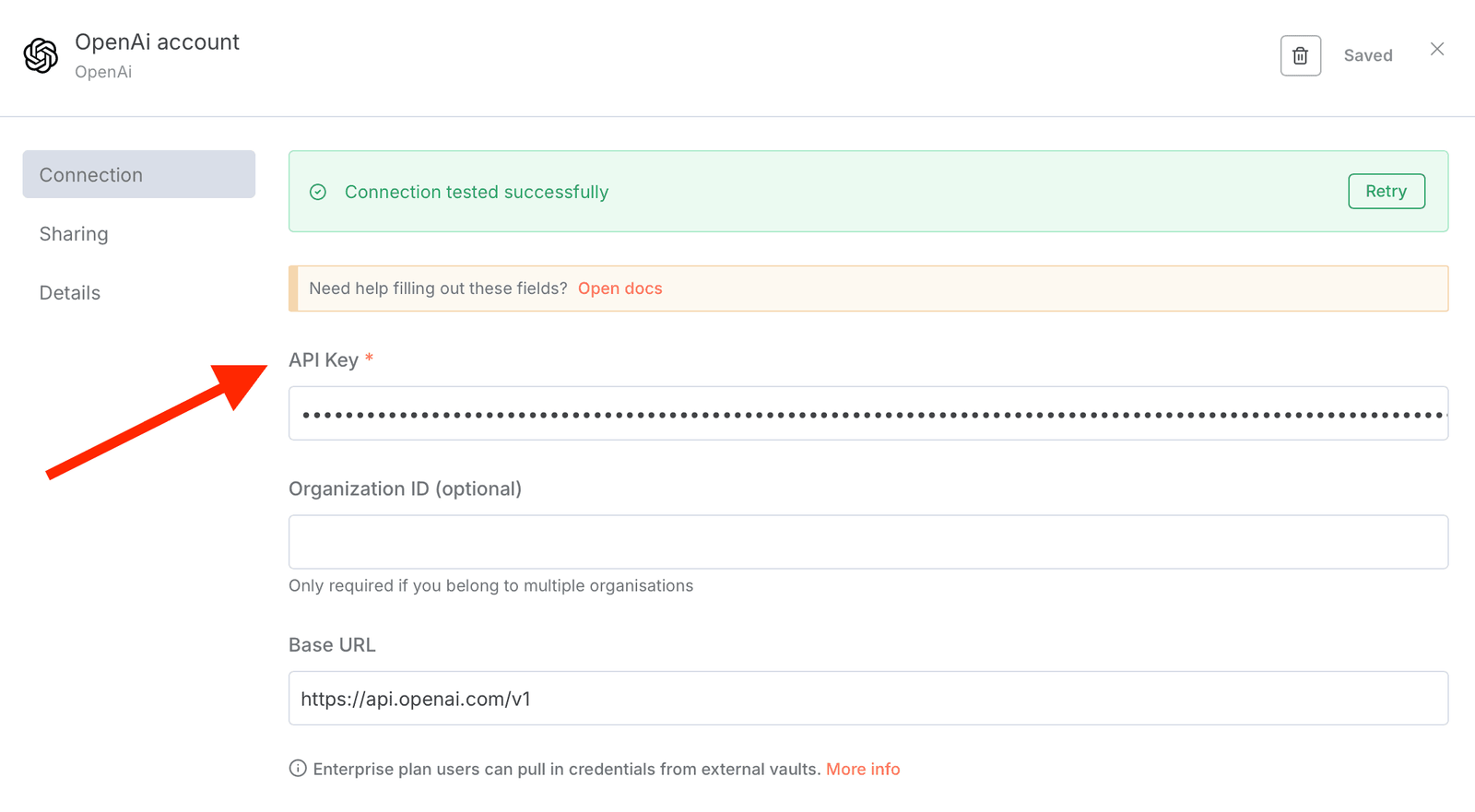
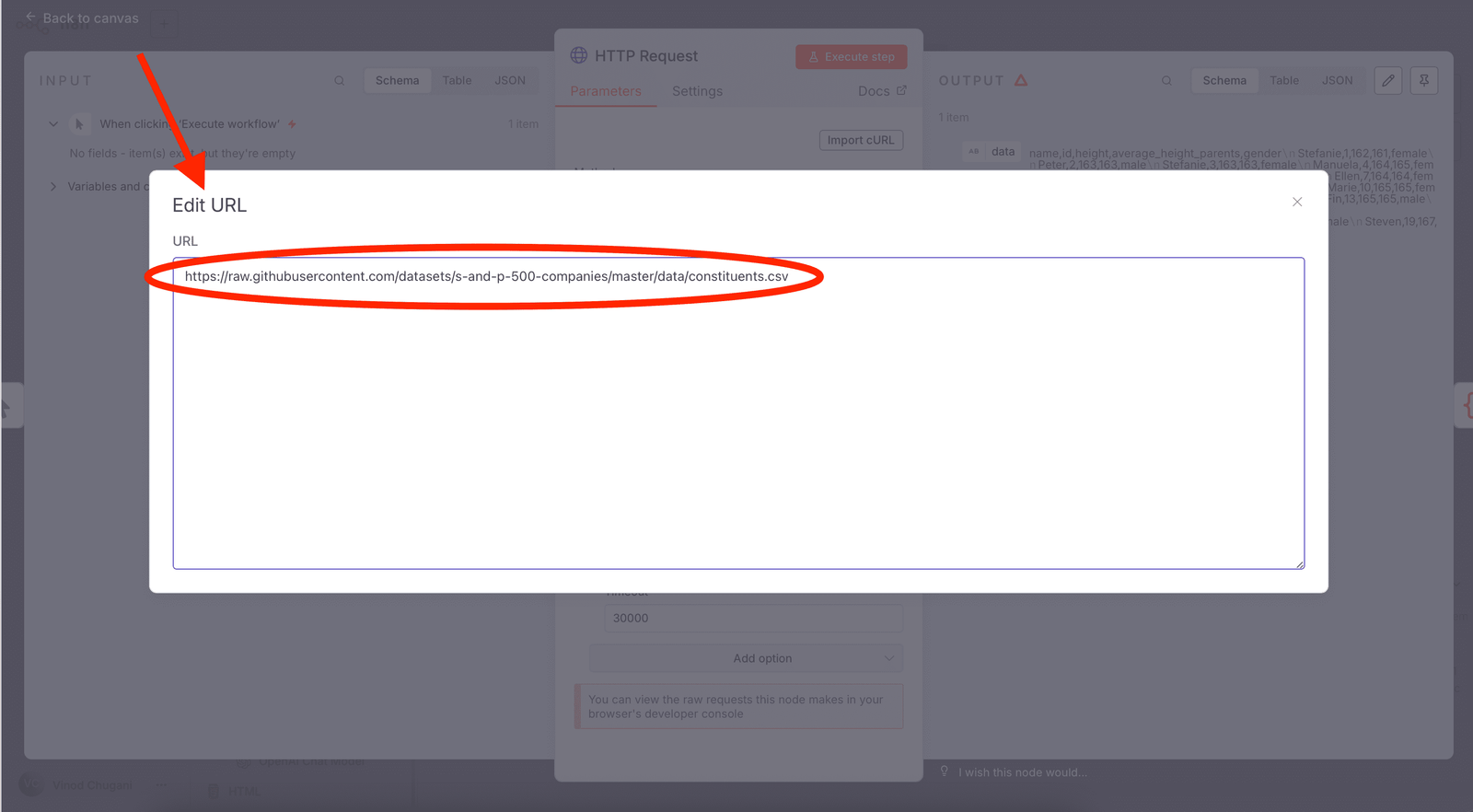
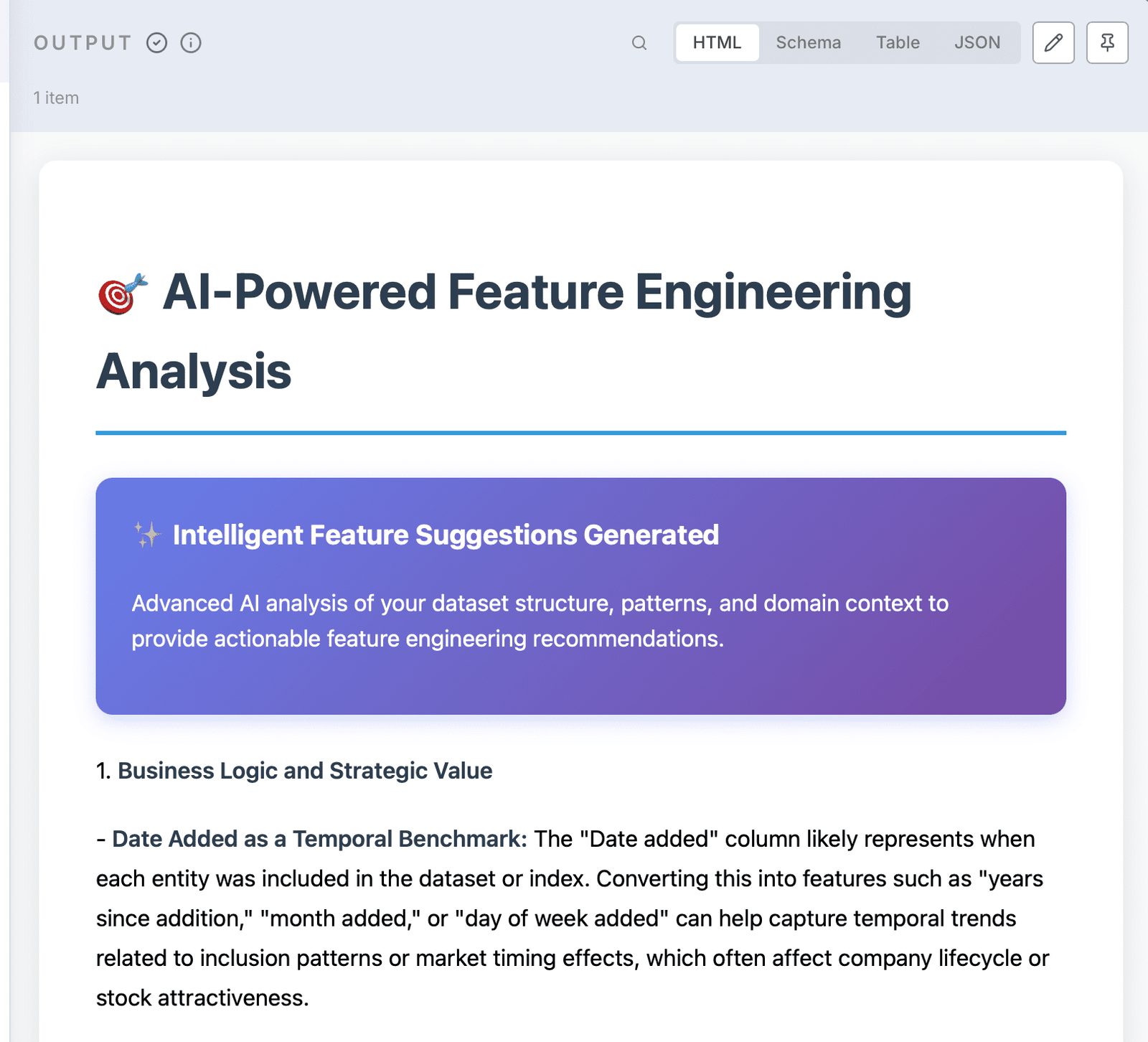

Image de l’auteur | Chatte
# Introduction
L’ingénierie des fonctionnalités est appelée «l’art» de la science des données pour une bonne raison – les scientifiques des données expérimentés développent cette intuition pour repérer des fonctionnalités significatives, mais ces connaissances sont difficiles à partager entre les équipes. Vous verrez souvent des scientifiques des données juniors passer des heures à réfléchir à des caractéristiques potentielles, tandis que les personnes seniors finissent par répéter les mêmes modèles d’analyse sur différents projets.
Voici la chose que la plupart des équipes de données rencontrent: les fonctionnalités de l’ingénierie nécessitent à la fois l’expertise du domaine et l’intuition statistique, mais l’ensemble du processus reste assez manuel et incohérent d’un projet à l’autre. Un scientifique supérieur des données pourrait immédiatement apercevoir que les ratios de capitalisation boursière pourraient prédire les performances du secteur, tandis que quelqu’un plus récent de l’équipe pourrait complètement manquer ces transformations évidentes.
Et si vous pouviez utiliser l’IA pour générer instantanément des recommandations d’ingénierie de fonctionnalités stratégiques? Ce flux de travail aborde un vrai problème de mise à l’échelle: transformer l’expertise individuelle en intelligence à l’échelle de l’équipe grâce à une analyse automatisée qui suggère des fonctionnalités basées sur des modèles statistiques, le contexte du domaine et la logique métier.
# L’avantage de l’IA dans l’ingénierie des fonctionnalités
La plupart de l’automatisation se concentre sur l’efficacité – accélérant les tâches répétitives et réduisant les travaux manuels. Mais ce flux de travail montre la science des données AI-Augmentation en action. Au lieu de remplacer l’expertise humaine, il amplifie la reconnaissance des modèles dans différents domaines et niveaux d’expérience.
S’appuyant sur la Fondation Visual Workflow de N8N, nous vous montrerons comment intégrer les LLM pour les suggestions de fonctionnalités intelligentes. Alors que l’automatisation traditionnelle gère les tâches répétitives, l’intégration de l’IA s’attaque aux parties créatives de la science des données – générer des hypothèses, identifier les relations et suggérer des transformations spécifiques au domaine.
Voici où N8N brille vraiment: vous pouvez connecter en douceur différentes technologies. Combinez le traitement des données, l’analyse de l’IA et les rapports professionnels sans sauter entre les outils ou la gestion de l’infrastructure complexe. Chaque flux de travail devient un pipeline d’intelligence réutilisable que toute votre équipe peut exécuter.
# La solution: un pipeline d’analyse d’IA à 5 nœuds
Notre flux de travail d’ingénierie des fonctionnalités intelligents utilise cinq nœuds connectés qui transforment les ensembles de données en recommandations stratégiques:
- Déclencheur manuel – commence une analyse à la demande pour tout ensemble de données
- Demande HTTP – Saisissez les données des URL ou des API publiques
- Noeud de code – Effectue une analyse statistique complète et une détection de modèles
- Chaîne LLM de base + Openai – génère des stratégies d’ingénierie des caractéristiques contextuelles
- Nœud html – Crée des rapports professionnels avec des idées générées par l’AI
# Construire le flux de travail: implémentation étape par étape
// Condition préalable
// Étape 1: Importez et configurez le modèle
- Télécharger le fichier de workflow
- Ouvrez N8N et cliquez sur «Importer à partir du fichier»
- Sélectionnez le fichier JSON téléchargé – les cinq nœuds apparaissent automatiquement
- Enregistrer le workflow sous le nom de «pipeline d’ingénierie des caractéristiques AI»
Le modèle importé a une logique d’analyse sophistiquée et des stratégies d’incitation à l’IA déjà créées pour une utilisation immédiate.
// Étape 2: Configurer l’intégration OpenAI
- Cliquez sur le nœud «Openai Chat Model»
- Créez un nouvel diplôme avec votre clé API OpenAI
- Sélectionnez «GPT-4.1-MINI» pour un solde optimal des coûts de performance
- Tester la connexion – vous devriez voir une authentification réussie
Si vous avez besoin d’une aide supplémentaire pour créer votre première clé API OpenAI, veuillez vous référer à notre guide étape par étape sur API Openai pour les débutants.
// Étape 3: Personnalisez pour votre ensemble de données
- Cliquez sur le nœud de demande HTTP
- Remplacez l’URL par défaut par notre Ensemble de données S&P 500:
https://raw.githubusercontent.com/datasets/s-and-p-500-companies/master/data/constituents.csv - Vérifiez les paramètres de délai d’attente (30 secondes ou 30000 millisecondes gère la plupart des ensembles de données)
Le flux de travail s’adapte automatiquement à différentes structures CSV, types de colonnes et modèles de données sans configuration manuelle.
// Étape 4: Exécuter et analyser les résultats
- Cliquez sur «Exécuter Workflow» dans la barre d’outils
- Exécution du nœud de surveillance – chacun devient vert une fois terminé
- Cliquez sur le nœud HTML et sélectionnez l’onglet ‘HTML’ pour votre rapport généré par AI-AI
- Revoir les recommandations d’ingénierie des fonctionnalités et la justification des entreprises
Ce que vous obtiendrez:
L’analyse de l’IA fournit des recommandations étonnamment détaillées et stratégiques. Pour notre ensemble de données S&P 500, il identifie des combinaisons de fonctionnalités puissantes telles que les backts d’âge de l’entreprise (startup, croissance, mature, héritage) et les interactions de location sectorielle qui révèlent les industries régionalement dominantes. Le système suggère que les modèles temporels des dates de listing, des stratégies de codage hiérarchique pour les catégories de haute cardinalité comme les sous-industries GICS et les relations entre les colonnes telles que les interactions d’âge par secteur qui saisissent la façon dont la maturité de l’entreprise affecte les performances différemment des secteurs. Vous recevrez des conseils de mise en œuvre spécifiques pour la modélisation des risques d’investissement, les stratégies de construction de portefeuille et les approches de segmentation du marché – toutes fondées sur un raisonnement statistique solide et une logique métier qui va bien au-delà des suggestions de fonctionnalités génériques.
# Dive technique profonde: le moteur de renseignement
// Analyse avancée des données (nœud de code):
L’intelligence du workflow commence par une analyse statistique complète. Le nœud de code examine les types de données, calcule les distributions, identifie les corrélations et détecte les modèles qui éclairent les recommandations de l’IA.
Les capacités clés comprennent:
- Détection automatique du type de colonne (numérique, catégorique, datetime)
- Analyse de la valeur manquante et évaluation de la qualité des données
- Identification des candidats de corrélation pour les fonctionnalités numériques
- Détection catégorielle à haute cardinalité pour les stratégies de codage
- Ratio potentiel et suggestions de terme d’interaction
// Ingénierie rapide de l’IA (chaîne LLM):
L’intégration LLM utilise une incitation structurée pour générer des recommandations consacrées au domaine. L’invite comprend les statistiques de l’ensemble de données, les relations de colonne et le contexte commercial pour produire des suggestions pertinentes.
L’IA reçoit:
- Structure et métadonnées de l’ensemble de données complètes
- Résumétes statistiques pour chaque colonne
- Modèles et relations identifiées
- Indicateurs de qualité des données
// Génération de rapports professionnels (nœud HTML):
La sortie finale transforme le texte de l’IA en un rapport formaté professionnellement avec un style, une organisation de section et une hiérarchie visuelle appropriés adaptés au partage des parties prenantes.
# Tester avec différents scénarios
// Ensemble de données de financement (exemple actuel):
Les données des sociétés S&P 500 génèrent des recommandations axées sur les mesures financières, l’analyse du secteur et les fonctionnalités de positionnement du marché.
// Ensembles de données alternatifs à essayer:
- Données sur les conseils du restaurant: Génère des modèles de comportement des clients, des indicateurs de qualité de service et des informations de l’industrie hôtelière
- Série chronologique des passagers des compagnies aériennes: Suggère des tendances saisonnières, des fonctionnalités de prévision de croissance et des analyses de l’industrie du transport
- La voiture s’écrase par état: Recommande les mesures d’évaluation des risques, les indices de sécurité et les fonctionnalités d’optimisation de l’industrie de l’assurance
Chaque domaine produit des suggestions de caractéristiques distinctes qui s’alignent sur les modèles d’analyse spécifiques à l’industrie et les objectifs commerciaux.
# Étapes suivantes: Mise à l’échelle de la science des données assistée par l’IA
// 1. Intégration avec les magasins de fonctionnalités
Connectez la sortie du flux de travail dans des magasins de fonctions comme Festin ou Tecton Pour la création et la gestion automatisées de pipelines de fonctionnalités.
// 2. Validation automatisée des fonctionnalités
Ajoutez des nœuds qui testent automatiquement les fonctionnalités suggérées par rapport aux performances du modèle pour valider les recommandations de l’IA avec des résultats empiriques.
// 3. Caractéristiques de collaboration d’équipe
Étendez le flux de travail pour inclure des notifications Slack ou une distribution par e-mail, partageant des informations sur l’IA entre les équipes de science des données pour le développement de fonctionnalités collaboratives.
// 4. Intégration du pipeline ML
Connectez-vous directement aux pipelines d’entraînement dans des plates-formes comme Kubeflow ou Mlflowimplémentant automatiquement les suggestions de fonctionnalités de grande valeur dans les modèles de production.
# Conclusion
Ce flux de travail d’ingénierie des fonctionnalités alimentés en AI montre comment N8N plie les capacités d’IA de pointe avec des opérations pratiques de science des données. En combinant des analyses automatisées, des recommandations intelligentes et des rapports professionnels, vous pouvez mettre à l’échelle l’expertise d’ingénierie des fonctionnalités dans l’ensemble de votre organisation.
La conception modulaire du workflow le rend précieux pour les équipes de données travaillant dans différents domaines. Vous pouvez adapter la logique d’analyse pour des industries spécifiques, modifier les invites d’IA pour des cas d’utilisation particuliers et personnaliser les rapports pour différents groupes de parties prenantes, le tout dans l’interface visuelle de N8N.
Contrairement aux outils d’IA autonomes qui fournissent des suggestions génériques, cette approche comprend votre contexte de données et votre domaine commercial. La combinaison de l’analyse statistique et de l’intelligence de l’IA crée des recommandations qui sont à la fois techniquement solides et stratégiquement pertinentes.
Plus important encore, ce flux de travail transforme l’ingénierie d’une compétence individuelle en une capacité organisationnelle. Les scientifiques des données juniors ont accès à des informations de niveau supérieur, tandis que les praticiens expérimentés peuvent se concentrer sur la stratégie de niveau supérieur et l’architecture modèle au lieu du brainstorming des fonctionnalités répétitives.
Né en Inde et élevé au Japon, Vinod apporte une perspective mondiale à l’enseignement des sciences des données et de l’apprentissage automatique. Il comble le fossé entre les technologies émergentes de l’IA et la mise en œuvre pratique des professionnels du travail. Vinod se concentre sur la création de voies d’apprentissage accessibles pour des sujets complexes tels que l’IA agentique, l’optimisation des performances et l’ingénierie de l’IA. Il se concentre sur les implémentations pratiques de l’apprentissage automatique et le mentorat de la prochaine génération de professionnels des données grâce à des sessions en direct et à des conseils personnalisés.
Source link



