
8 façons d’étendre vos charges de travail en science des données
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 18 minutes de lecture

Contenu sponsorisé
Combien de temps passez-vous à combattre vos outils au lieu de résoudre des problèmes? Chaque scientifique des données a été là: réduction de réduction d’un ensemble de données, car il ne rentrera pas dans la mémoire ou ne pira pas un moyen de laisser un utilisateur commercial interagir avec un modèle d’apprentissage automatique.
L’environnement idéal s’écarte afin que vous puissiez vous concentrer sur l’analyse. Cet article couvre huit méthodes pratiques dans BigQuery conçues pour faire exactement cela, de l’utilisation d’agents alimentés par l’IA à la service des modèles ML directement à partir d’une feuille de calcul.
1. Apprentissage automatique dans vos feuilles de calcul
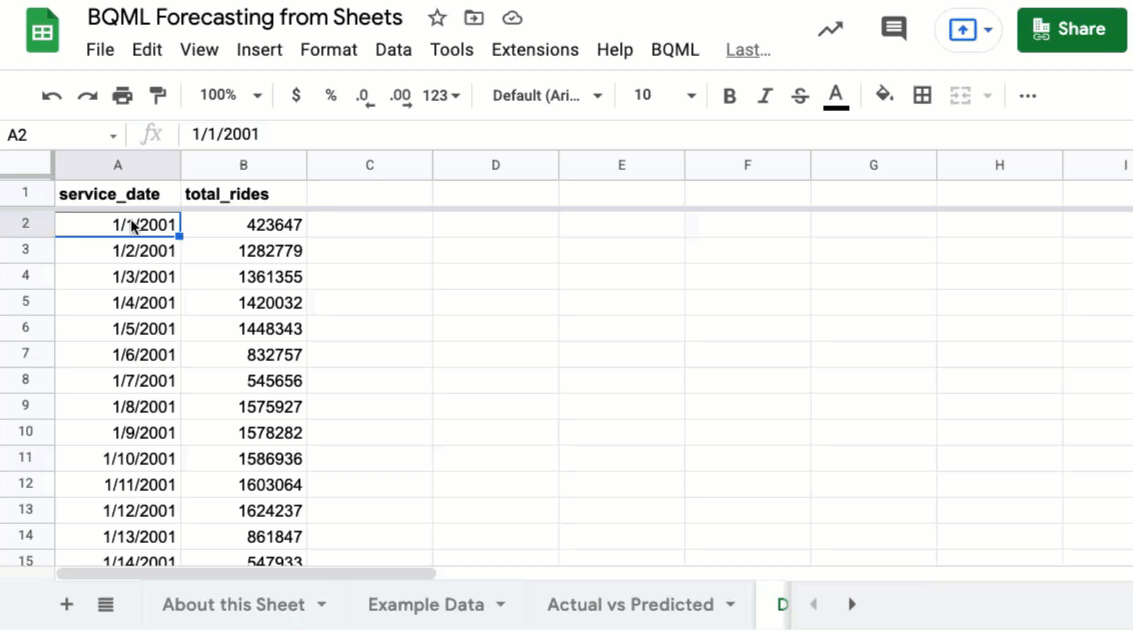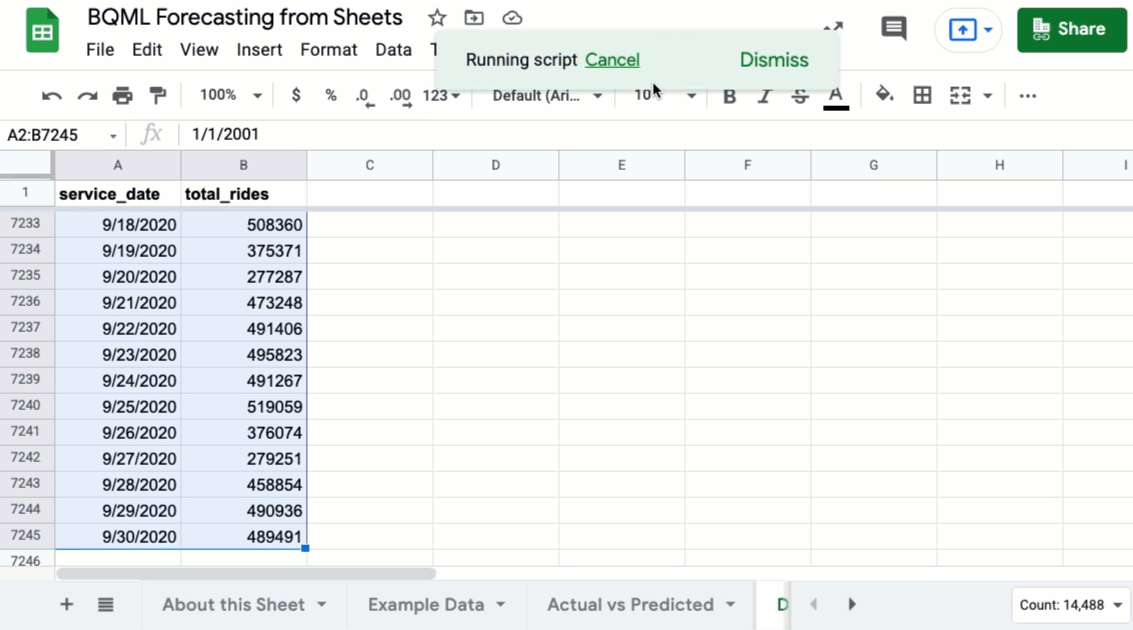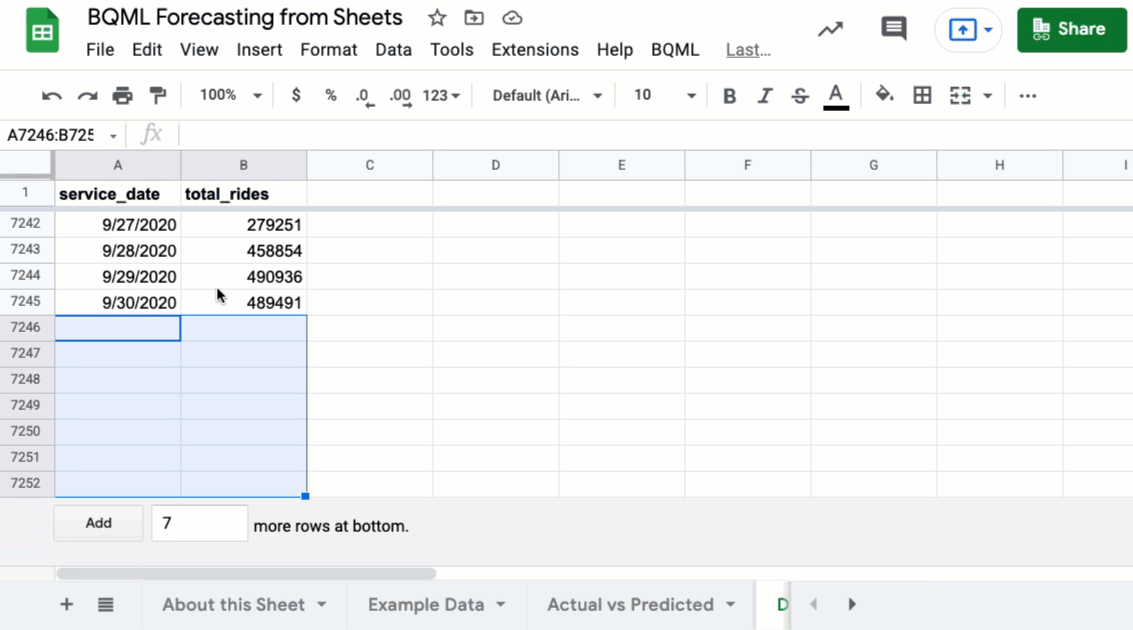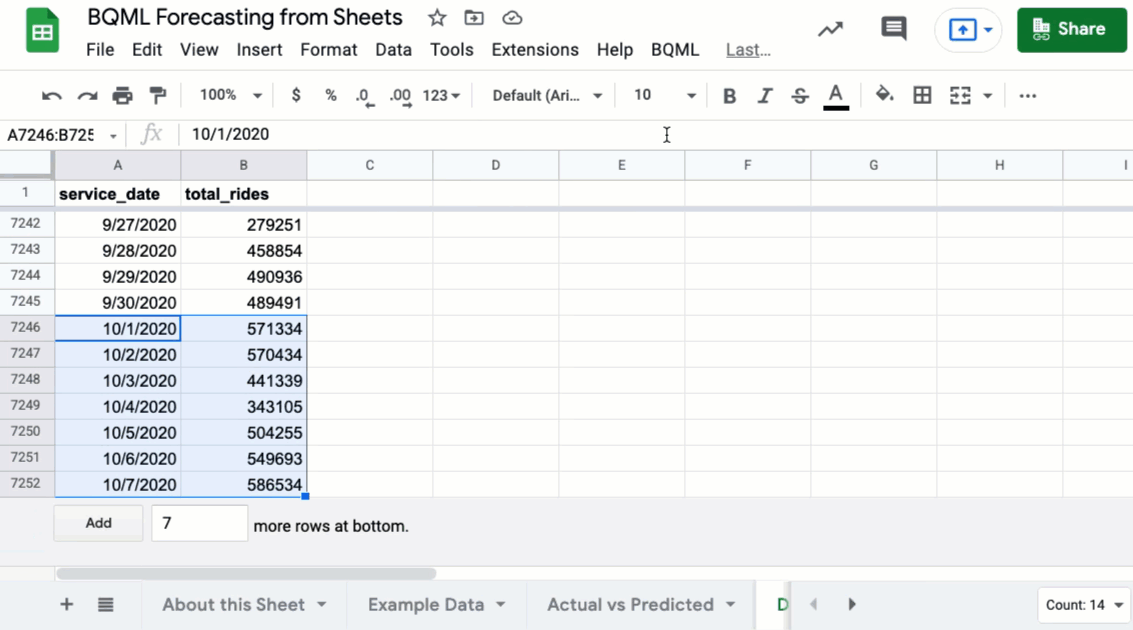
Formation et prédiction BQML à partir d’une feuille Google
De nombreuses conversations de données commencent et se terminent par une feuille de calcul. Ils sont familiers, faciles à utiliser et idéaux pour la collaboration. Mais que se passe-t-il lorsque vos données sont trop grandes pour une feuille de calcul, ou lorsque vous souhaitez exécuter une prédiction sans écrire un tas de code? Feuilles connectées Aide en vous permettant d’analyser des milliards de lignes de données BigQuery à partir de l’interface Google Sheets. Tous les calculs, graphiques et tables de pivot sont alimentés par BigQuery dans les coulisses.
En allant plus loin, vous pouvez également accéder aux modèles avec lesquels vous avez construit BigQuery Machine Learning (BQML). Imaginez que vous avez un modèle BQML qui prédit les prix du logement. Avec des feuilles connectées, un utilisateur d’entreprise peut ouvrir une feuille, entrer des données pour une nouvelle propriété (pieds carrés, nombre de chambres, emplacement) et une formule peut appeler un modèle BQML pour retourner une estimation des prix. Aucun Python ou API ne nécessaire – juste une formule de feuilles appelant un modèle. C’est un moyen puissant d’exposer l’apprentissage automatique à des équipes non techniques.
2. Pas de bacs à sable BigQuery et de carnets Colab
Le début des entrepôts de données d’entreprise implique souvent des frictions, comme la création d’un compte de facturation. Le BigQuery Sandbox Supprime cette barrière, vous permettant de demander jusqu’à 1 téraoctet de données par mois. Aucune carte de crédit requise. C’est une excellente façon sans coût de commencer à apprendre et à expérimenter des analyses à grande échelle.
En tant que scientifique des données, vous pouvez accéder à votre bac à sable BigQuery à partir d’un Cahier de colab. Avec seulement quelques lignes de code d’authentification, vous pouvez exécuter des requêtes SQL directement à partir d’un ordinateur portable et extraire les résultats dans un Python DataFrame pour l’analyse. Ce même environnement de cahier peut même agir en tant que partenaire d’IA pour vous aider à planifier votre analyse et à écrire du code.
3. Votre partenaire alimenté par AI dans les cahiers Colab
Agent de science des données dans un cahier Colab (séquences raccourcies, résultats à des fins d’illustration)
Les cahiers Colab sont maintenant Une expérience de l’IA-First Conçu pour accélérer votre flux de travail. Vous pouvez générer du code à partir du langage naturel, obtenir des explications d’erreur automatique et discuter avec un assistant à côté de votre code.
Les cahiers Colab ont également un agent de science des données intégré. Considérez-le comme un expert en ML avec lequel vous pouvez collaborer. Commencez par un ensemble de données – comme un CSV local ou une table BigQuery – et un objectif de haut niveau, comme «Créer un modèle pour prédire le désabonnement du client». L’agent crée un plan avec des étapes suggérées (par exemple le nettoyage des données, l’ingénierie des fonctionnalités, la formation du modèle) et écrit le code.
Et vous êtes toujours en contrôle. L’agent génère du code directement dans des cellules de carnet, mais n’exécute rien seul. Vous pouvez consulter et modifier chaque cellule avant de décider quoi exécuter, ou même demander à l’agent de repenser son approche et d’essayer différentes techniques.
4. Échec de vos workflows Pandas avec BigQuery DataFrames
De nombreux scientifiques des données vivent dans des ordinateurs portables et utilisent des données de données Pandas pour la manipulation des données. Mais il y a une limite bien connue: toutes les données que vous traitez doivent s’adapter à la mémoire de votre machine. MemoryError Les exceptions sont trop courantes, vous obligeant à réprimer vos données dès le début.
C’est le problème exact BigQuery DataFrames résout. Il fournit une API Python intentionnellement similaire aux pandas. Au lieu d’exécuter localement, il traduit vos commandes en SQL et les exécute sur le moteur BigQuery. Cela signifie que vous pouvez travailler avec des ensembles de données à l’échelle de terabyte à partir de votre cahier, avec une API familière, et aucune inquiétude concernant les contraintes de mémoire. Le même concept s’applique à la formation des modèles, avec une API de type Scikit-Learn qui pousse la formation des modèles à BigQuery ML.
5. Spark ML dans BigQuery Studio Notebooks
Exemple de carnet Spark ML dans BigQuery Studio
Apache Spark est un outil utile de l’ingénierie des fonctionnalités à la formation des modèles, mais la gestion de l’infrastructure a toujours été un défi. Sans serveur pour Apache Spark Vous permet d’exécuter du code Spark, y compris des travaux utilisant des bibliothèques comme XGBoost, Pytorch et Transformers, sans avoir à provisionner un cluster. Vous pouvez développer de manière interactive À partir d’un cahier directement dans BigQuery, vous permettant de vous concentrer sur le développement de modèles, tandis que BigQuery gère l’infrastructure.
Vous pouvez utiliser Serverless Spark pour fonctionner sur les mêmes données (et le même modèle de gouvernance) dans votre entrepôt BigQuery.
6. Ajouter un contexte externe avec des ensembles de données publics
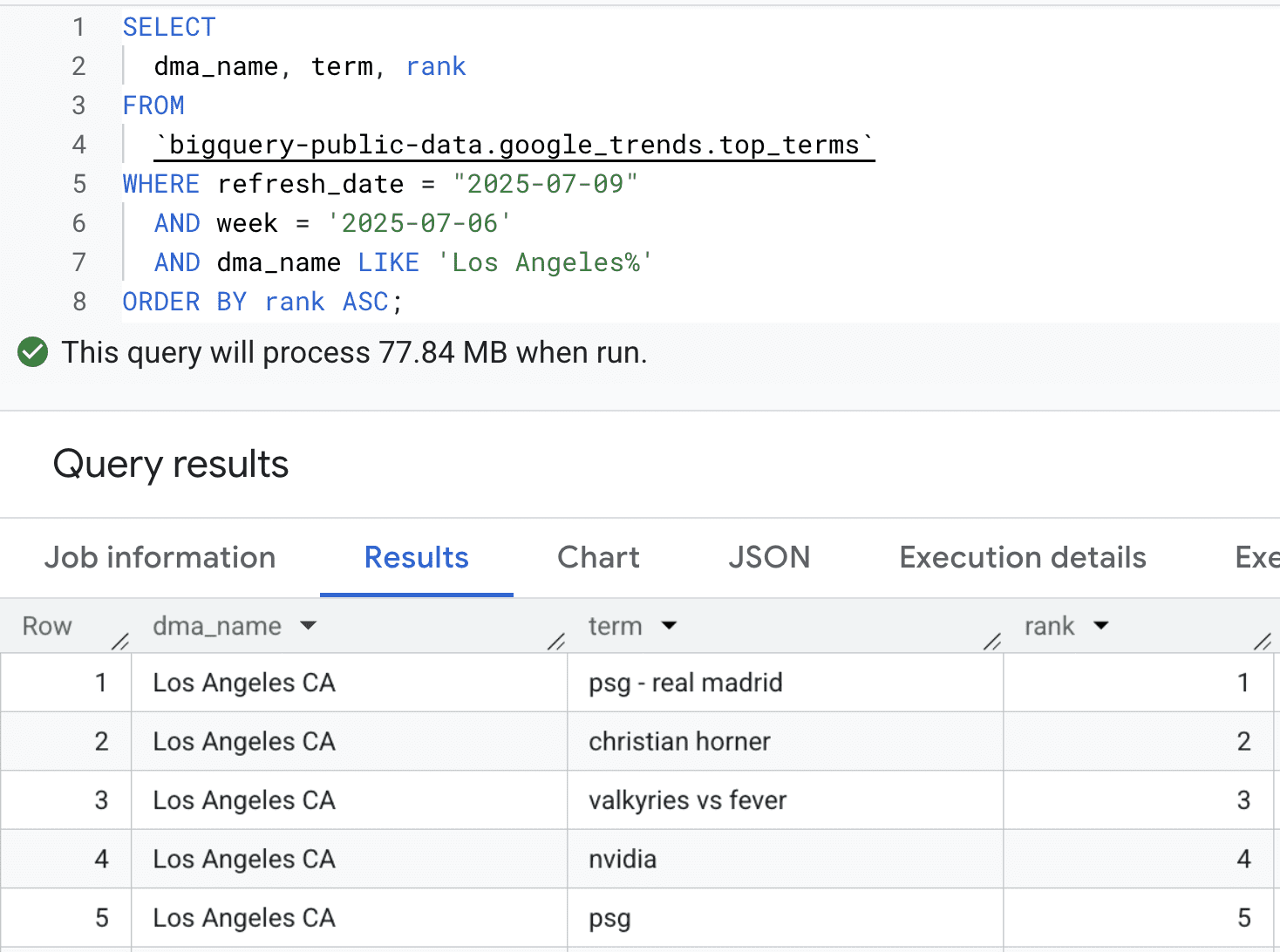
Top 5 des termes de tendance dans la région de Los Angeles début juillet 2025
Vos données de première partie vous indiquent ce qui s’est passé, mais ne peut pas toujours expliquer pourquoi. Pour trouver ce contexte, vous pouvez rejoindre vos données avec une grande collection d’ensembles de données publics disponibles dans BigQuery.
Imaginez que vous êtes un scientifique des données pour une marque de vente au détail. Vous voyez un pic de vente pour un imperméable dans le nord-ouest du Pacifique. Était-ce votre récente campagne de marketing, ou autre chose? En rejoignant vos données de vente avec le Ensemble de données Google Trends Dans BigQuery, vous pouvez rapidement voir si les requêtes de recherche pour «veste étanche» ont également augmenté dans la même région et la même période.
Ou disons que vous planifiez un nouveau magasin. Vous pouvez utiliser le Ensemble de données de places Insights Pour analyser les modèles de trafic et la densité commerciale dans les quartiers potentiels, les superposer en plus de vos informations clients pour choisir le meilleur emplacement. Ces ensembles de données publics vous permettent de créer des modèles plus riches qui expliquent les facteurs du monde réel.
7. Analyse géospatiale à grande échelle
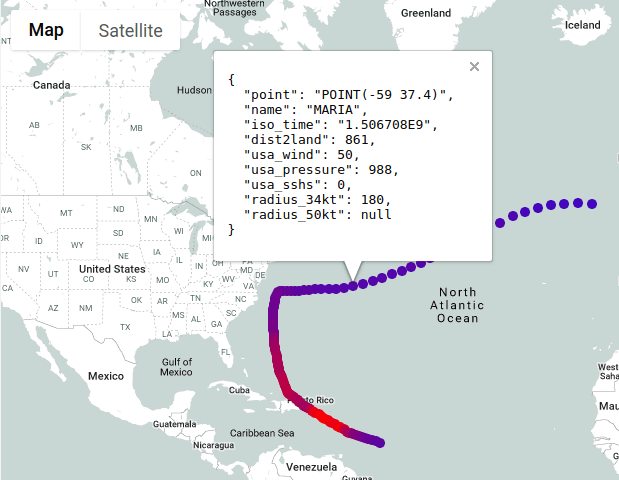
BigQuery Geo Viz Carte d’un ouragan, en utilisant la couleur pour indiquer le rayon et la vitesse du vent
Les fonctionnalités de l’emplacement du bâtiment pour un modèle peuvent être complexes, mais BigQuery simplifie cela en soutenant un GEOGRAPHY type de données et standard SIG fonctionne dans SQL. Cela vous permet de concevoir des caractéristiques spatiales directement à la source. Par exemple, si vous construisez un modèle pour prédire les prix des biens immobiliers, vous pouvez utiliser une fonction comme ST_DWithin pour calculer le nombre de titres de transport en commun dans un rayon d’un mile pour chaque propriété. Vous pouvez ensuite utiliser cette valeur directement comme entrée dans votre modèle.
Vous pouvez aller plus loin avec Google Earth Engine L’intégration, qui apporte des pétaoctets d’imagerie satellite et de données environnementales dans BigQuery. Pour ce même modèle immobilier, vous pouvez interroger les données de Earth Engine pour ajouter des fonctionnalités telles que le risque d’inondation historique ou même la densité de la couverture des arbres. Cela vous aide à créer des modèles beaucoup plus riches en augmentant vos données commerciales avec des informations environnementales à l’échelle de la planète.
8. Donnez un sens aux données de journal
La plupart des gens pensent à BigQuery pour les données analytiques, mais c’est aussi une destination puissante pour les données opérationnelles. Vous pouvez acheminer tous votre Données de journalisation du cloud à BigQuerytransformant les journaux de texte non structurés en ressources interrogables. Cela vous permet d’exécuter SQL entre les journaux de tous vos services pour diagnostiquer les problèmes, suivre les performances ou analyser les événements de sécurité.
Pour un scientifique des données, ces données de journalisation du cloud sont une source riche pour créer des prédictions. Imaginez enquêter sur une baisse de l’activité utilisateur. Après avoir identifié un message d’erreur dans les journaux, vous pouvez utiliser Recherche de vecteur BigQuery Pour trouver des journaux sémantiquement similaires, même s’ils ne contiennent pas exactement le même texte. Cela pourrait aider à révéler des problèmes connexes, comme «un jeton utilisateur invalide» et «l’authentification a échoué», qui font partie de la même cause profonde. Vous pouvez ensuite utiliser ces données étiquetées pour former un modèle de détection d’anomalies qui signale les modèles de manière proactive.
Conclusion
Espérons que ces exemples déclenchent de nouvelles idées pour votre prochain projet. De la mise à l’échelle de Pandas DataFrames à la conduite d’ingénierie avec des données géographiques, l’objectif est de vous aider à travailler à grande échelle avec des outils familiers.
Prêt à donner un coup de feu? Vous pouvez commencer à explorer sans frais aujourd’hui dans le BigQuery Sandbox!
Auteur: Jeff Nelson, ingénieur des relations avec les développeurs
Source link



