
Construire des pipelines de données de bout en bout: de l’ingestion de données à l’analyse
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 18 minutes de lecture
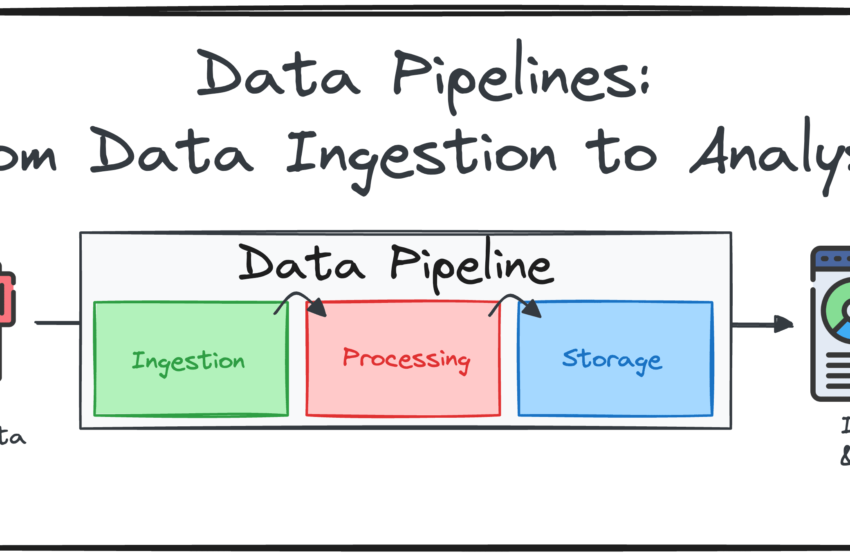
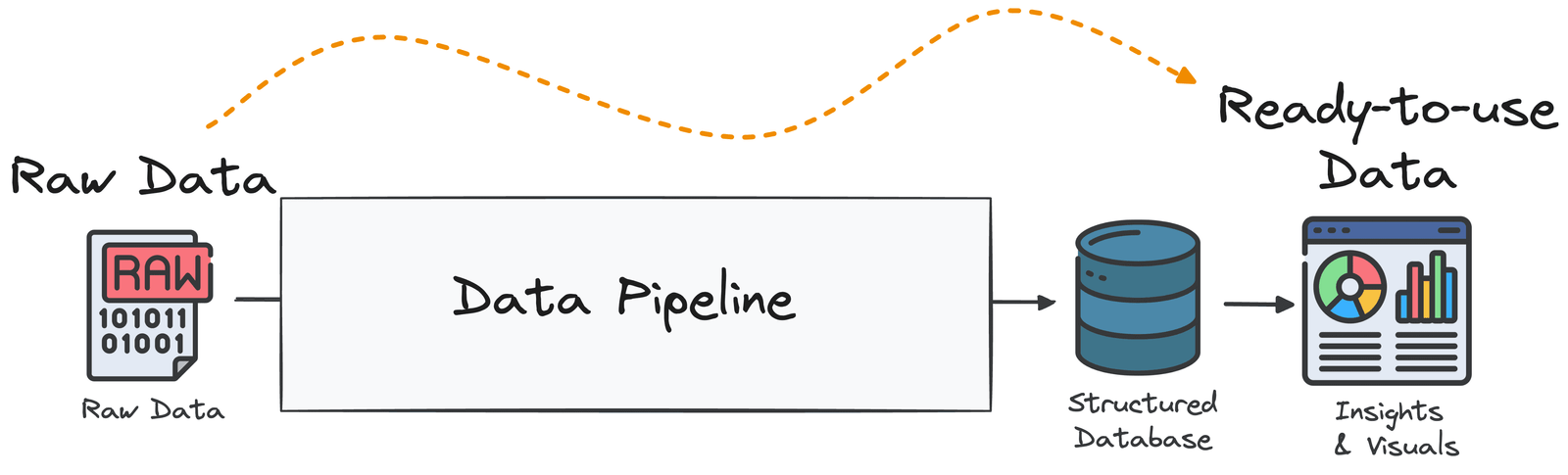
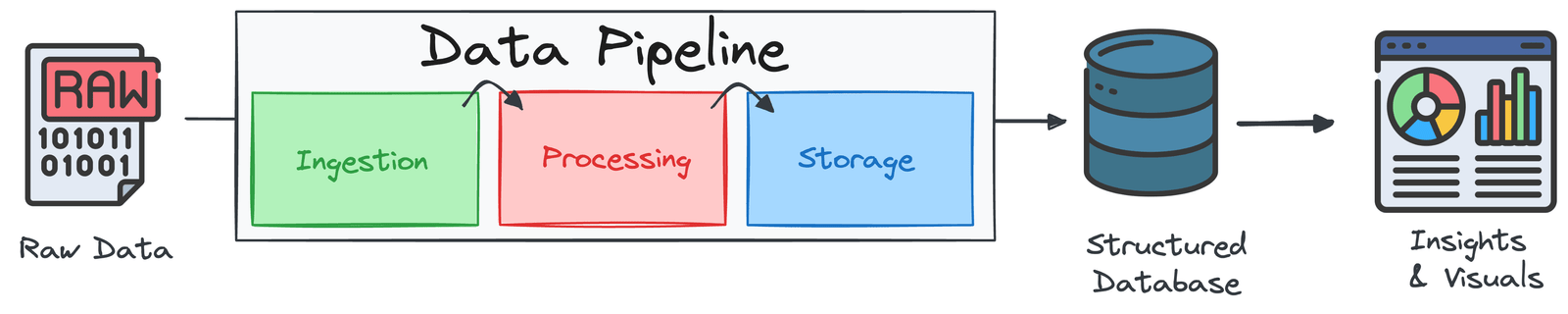
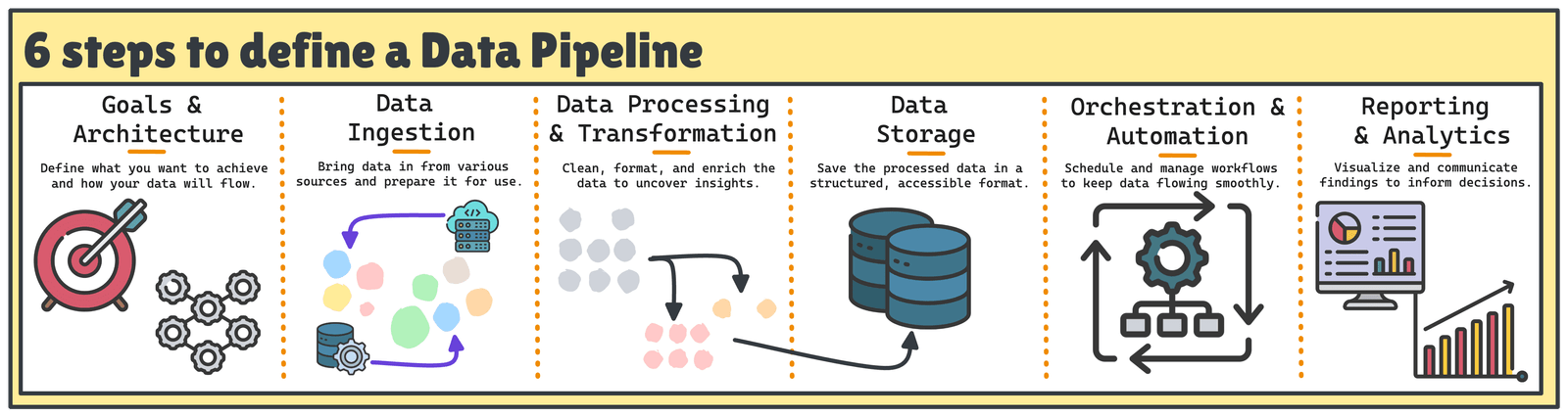
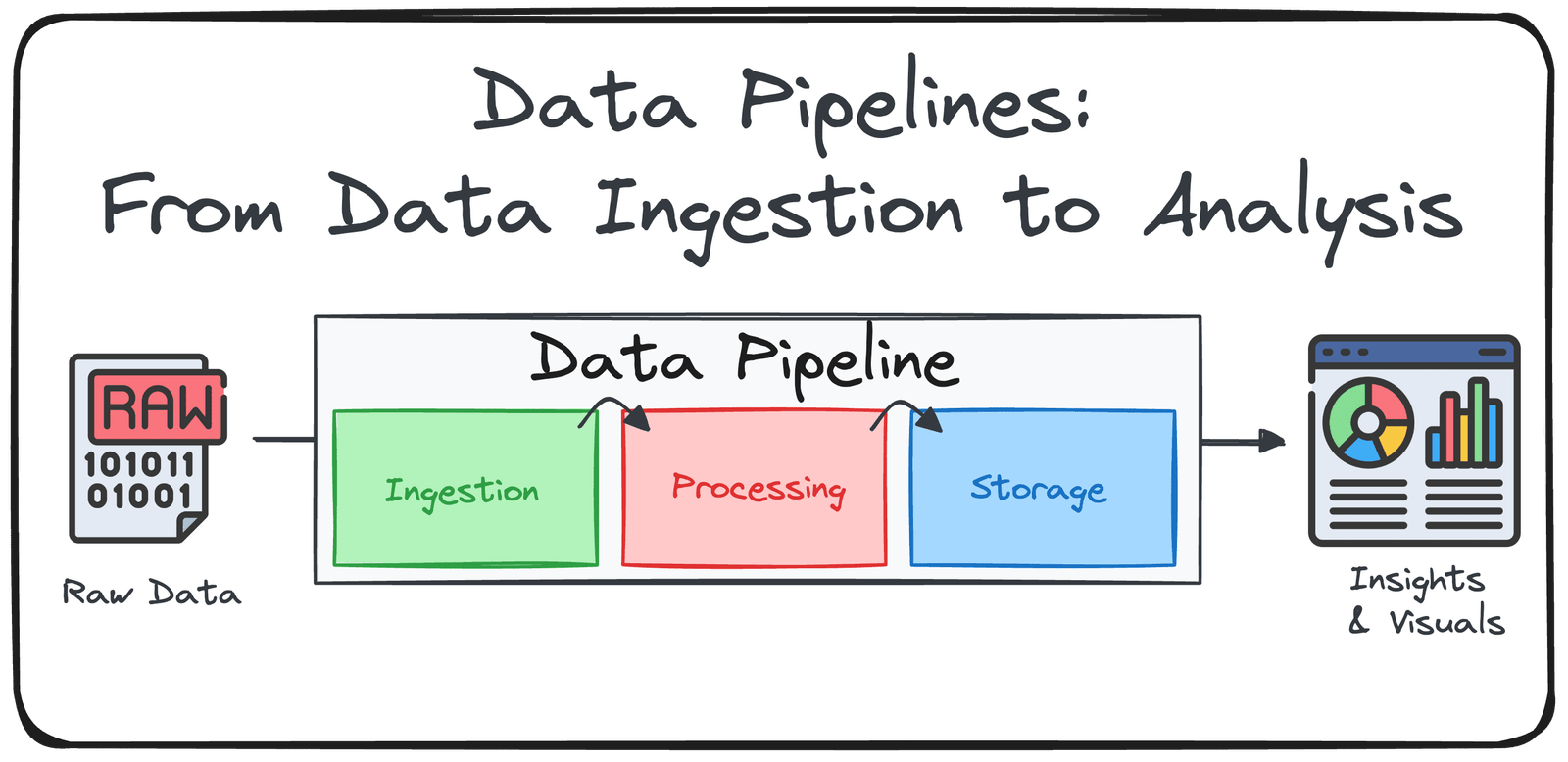
Image par auteur
La livraison des bonnes données au bon moment est un besoin principal de toute organisation dans la société axée sur les données. Mais soyons honnêtes: la création d’un pipeline de données fiable, évolutif et maintenable n’est pas une tâche facile. Cela nécessite une planification réfléchie, une conception intentionnelle et une combinaison de connaissances commerciales et d’expertise technique. Qu’il s’agisse d’intégrer plusieurs sources de données, de gérer les transferts de données ou simplement d’assurer des rapports en temps opportun, chaque composant présente ses propres défis.
C’est pourquoi aujourd’hui je voudrais souligner ce qu’est un pipeline de données et discuter des composantes les plus critiques de la création d’un.
Qu’est-ce qu’un pipeline de données?
Avant d’essayer de comprendre comment déployer un pipeline de données, vous devez comprendre ce que c’est et pourquoi il est nécessaire.
Un pipeline de données est une séquence structurée d’étapes de traitement conçues pour transformer les données brutes en un format utile et analysable pour l’intelligence commerciale et la prise de décision. Pour le dire simplement, c’est un système qui collecte des données à partir de diverses sources, transforme, enrichit et l’optimise, puis la livre à une ou plusieurs destinations cibles.
Image par auteur
Il est d’une idée fausse courante d’assimiler un pipeline de données à toute forme de mouvement de données. Le simple déplacement de données brutes du point A au point B (par exemple, pour la réplication ou la sauvegarde) ne constitue pas un pipeline de données.
Pourquoi définir un pipeline de données?
Il existe plusieurs raisons de définir un pipeline de données lorsque vous travaillez avec les données:
- Modularité: composée d’étapes réutilisables pour une maintenance et une évolutivité faciles
- Tolérance aux défauts: peut se remettre des erreurs avec les mécanismes de journalisation, de surveillance et de réessayer
- Assurance de la qualité des données: valide les données pour l’intégrité, la précision et la cohérence
- Automatisation: fonctionne sur un calendrier ou un déclencheur, minimisant l’intervention manuelle
- Sécurité: protège les données sensibles avec les contrôles d’accès et le chiffrement
Les trois composants principaux d’un pipeline de données
La plupart des pipelines sont construits autour de l’ETL (Extraire, transformer, charger) ou elt (Extraire, charger, transformer) cadre. Les deux suivent les mêmes principes: le traitement de gros volumes de données efficacement et s’assurer qu’il est propre, cohérent et prêt à l’emploi.
Image par auteur
Décomposons chaque étape:
Composant 1: Ingestion de données (ou extrait)
Le pipeline commence par collecter des données brutes à partir de plusieurs sources de données comme les bases de données, les API, le stockage cloud, les appareils IoT, les CRM, les fichiers plats, etc. Les données peuvent arriver par lots (rapports horaires) ou sous forme de flux en temps réel (trafic Web en direct). Ses objectifs clés sont de se connecter en toute sécurité et de manière fiable à diverses sources de données et de collecter des données en mouvement (en temps réel) ou au repos (lot).
Il y a deux approches communes:
- Batch: planifier des tirages périodiques (quotidiennement, horaire).
- Streaming: utilisez des outils comme Kafka ou des API pilotés par événement pour ingérer des données en continu.
Les outils les plus courants à utiliser sont:
- Outils par lots: Airbyte, Fivetran, Apache NiFi, Scripts Python / SQL personnalisés
- API: pour les données structurées des services (Twitter, Eurostat, TripAdvisor)
- Stracage sur le Web: outils comme BeautifulSoup, Scrapy ou SCOPS SANS CODE
- Fichiers plats: CSV / Excel à partir de sites Web officiels ou de serveurs internes
Composant 2: Traitement et transformation des données (ou transformation)
Une fois ingérés, les données brutes doivent être affinées et préparées pour l’analyse. Cela implique le nettoyage, la normalisation, la fusion de ensembles de données et l’application de la logique commerciale. Ses objectifs clés sont d’assurer la qualité des données, la cohérence et la convivialité et d’aligner les données avec des modèles analytiques ou des besoins de rapport.
Il y a généralement plusieurs étapes considérées au cours de ce deuxième composant:
- Nettoyage: gérer les valeurs manquantes, supprimer les doublons, unifier les formats
- Transformation: appliquez le filtrage, l’agrégation, le codage ou le remodelage de la logique
- Validation: effectuez des vérifications d’intégrité pour garantir l’exactitude
- Fusion: combinez des ensembles de données à partir de plusieurs systèmes ou sources
Les outils les plus courants comprennent:
- DBT (outil de construction de données)
- Apache Spark
- Python (pandas)
- Pipelines basés sur SQL
Composant 3: livraison (ou charge) des données
Les données transformées sont livrées à sa destination finale, généralement un entrepôt de données (pour les données structurées) ou un lac de données (pour les données semi-non structurées). Il peut également être envoyé directement aux tableaux de bord, aux API ou aux modèles ML. Ses objectifs clés sont de stocker des données dans un format qui prend en charge la requête et l’évolutivité rapides et de permettre un accès en temps réel ou en temps proche de la prise de décision.
Les outils les plus populaires comprennent:
- Stockage cloud: Amazon S3, Storage Cloud Google
- Entrepôts de données: BigQuery, Snowflake, Databricks
- Sorties biologiques: tableaux de bord, rapports, API en temps réel
Six étapes pour créer un pipeline de données de bout en bout
La construction d’un bon pipeline de données implique généralement six étapes clés.
Les six étapes pour construire un pipeline de données robuste | Image par auteur
1. Définir les objectifs et l’architecture
Un pipeline réussi commence par une compréhension claire de son objectif et de l’architecture nécessaire pour la soutenir.
Questions clés:
- Quels sont les principaux objectifs de ce pipeline?
- Qui sont les utilisateurs finaux des données?
- À quel point les données doivent-elles être frais ou réels?
- Quels outils et modèles de données correspondent le mieux à nos exigences?
Actions recommandées:
- Clarifier les questions commerciales que votre pipeline vous aidera à répondre
- Dessinez un diagramme d’architecture de haut niveau pour aligner les parties prenantes techniques et commerciales
- Choisissez des outils et des modèles de données de conception en conséquence (par exemple, un schéma d’étoiles pour les rapports)
2. Ingestion de données
Une fois les objectifs définis, l’étape suivante consiste à identifier les sources de données et à déterminer comment ingérer les données de manière fiable.
Questions clés:
- Quelles sont les sources de données et dans quels formats sont-ils disponibles?
- L’ingestion devrait-elle se produire en temps réel, par lots ou les deux?
- Comment assurerez-vous l’exhaustivité et la cohérence des données?
Actions recommandées:
- Établir des connexions sécurisées et évolutives à des sources de données comme les API, les bases de données ou les outils tiers.
- Utilisez des outils d’ingestion tels que Airbyte, FiveTran, Kafka ou Connecteurs personnalisés.
- Implémentez les règles de validation de base pendant l’ingestion pour prendre les erreurs tôt.
3. Traitement et transformation des données
Avec les données brutes qui coulent, il est temps de les rendre utiles.
Questions clés:
- Quelles transformations sont nécessaires pour préparer des données pour l’analyse?
- Les données doivent-elles être enrichies avec des entrées externes?
- Comment les doublons ou les enregistrements non valides seront-ils gérés?
Actions recommandées:
- Appliquer des transformations telles que le filtrage, l’agrégation, la normalisation et l’adhésion aux ensembles de données
- Implémentez la logique commerciale et assurez la cohérence du schéma entre les tables
- Utilisez des outils comme DBT, Spark ou SQL pour gérer et documenter ces étapes
4. Stockage de données
Ensuite, choisissez comment et où stocker vos données traitées pour l’analyse et les rapports.
Questions clés:
- Devriez-vous utiliser un entrepôt de données, un lac de données ou une approche hybride (Lakehouse)?
- Quelles sont vos exigences en termes de coût, d’évolutivité et de contrôle d’accès?
- Comment structurerez-vous des données pour une requête efficace?
Actions recommandées:
- Sélectionnez des systèmes de stockage qui s’alignent avec vos besoins analytiques (par exemple, BigQuery, Snowflake, S3 + Athena)
- Schémas de conception qui optimisent pour la déclaration des cas d’utilisation
- Planifiez la gestion du cycle de vie des données, y compris l’archivage et la purge
5. Orchestration et automatisation
Le lien entre tous les composants nécessite une orchestration et une surveillance du flux de travail.
Questions clés:
- Quelles étapes dépendent les unes des autres?
- Que devrait se passer lorsqu’une étape échoue?
- Comment allez-vous surveiller, déboguer et entretenir vos pipelines?
Actions recommandées:
- Utilisez des outils d’orchestration comme le flux d’air, le préfet ou le dagster pour planifier et automatiser les workflows
- Configurer des politiques et des alertes de réessayer pour les échecs
- Version votre code de pipeline et modulariser pour la réutilisabilité
6. Rapports et analyses
Enfin, offrez de la valeur en exposant des informations aux parties prenantes.
Questions clés:
- Quels outils les analystes et les utilisateurs professionnels utiliseront-ils pour accéder aux données?
- À quelle fréquence les tableaux de bord devraient-ils mettre à jour?
- Quelles autorisations ou politiques de gouvernance sont nécessaires?
Actions recommandées:
- Connectez votre entrepôt ou votre lac à des outils BI comme Looker, Power BI ou Tableau
- Configurez des couches ou des vues sémantiques pour simplifier l’accès
- Surveiller l’utilisation du tableau de bord et les performances de rafraîchissement pour assurer la valeur continue
Conclusions
La création d’un pipeline de données complet ne consiste pas seulement à transférer des données, mais à autonomiser ceux qui en ont besoin pour prendre des décisions et agir. Ce processus organisé en six étapes vous permettra de construire des pipelines non seulement efficaces mais résilients et évolutifs.
Chaque phase du pipeline – l’ingestion, la transformation et la livraison – joue un rôle crucial. Ensemble, ils forment une infrastructure de données qui prend en charge les décisions basées sur les données, améliore l’efficacité opérationnelle et favorise de nouvelles voies pour l’innovation.
Josep Ferrer est un ingénieur en analyse de Barcelone. Il a obtenu son diplôme en génie physique et travaille actuellement dans le domaine de la science des données appliquée à la mobilité humaine. Il est un créateur de contenu à temps partiel axé sur la science et la technologie des données. Josep écrit sur tout ce qui concerne l’IA, couvrant l’application de l’explosion en cours sur le terrain.
Source link



