
AI dans la salle de classe: création et affectations de qualité avec chatppt
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 32 minutes de lecture

Auteur (s): Kseniia Baidina
Publié à l’origine sur Vers l’IA.
Il existe de nombreux articles sur la façon dont les étudiants utilisent Chatgpt pour terminer leurs devoirs – et ce que les professeurs devraient faire à ce sujet. Personnellement, je pense que les professeurs devraient encourager cela (si vous ne pouvez pas les battre, rejoindre eux), mais ce n’est pas l’objectif de cet article.
Ce que je veux souligner, c’est que les professeurs peuvent également utiliser Chatgpt pour gérer leurs propres «devoirs» plus efficacement. La création et la classement des affectations peuvent être fastidieuses, monotones – et parfois même ennuyeuses. Dans cet article, je vais partager comment j’utilise l’API ChatGpt pour automatiser à la fois la génération de tâches de devoirs et les soumissions d’étudiants.
Pourquoi l’API et pas seulement le chat régulier?
Vous pouvez faire tout cela en utilisant l’interface de chat, mais il y a un problème: l’évolutivité. Cela fonctionne bien si vous créez une seule affectation ou classez quelques réponses. Mais lorsque vous avez beaucoup d’étudiants et beaucoup de devoirs, tout faire manuellement devient trop long et inefficace.
Configurer l’API Chatgpt
Commençons par configurer l’accès à l’API Chatgpt. Si vous avez déjà fait cela auparavant, n’hésitez pas à ignorer cette partie.
Pour utiliser l’API, vous aurez besoin d’une clé API et d’une configuration de facturation, car l’API n’est pas gratuite. Voici comment commencer:
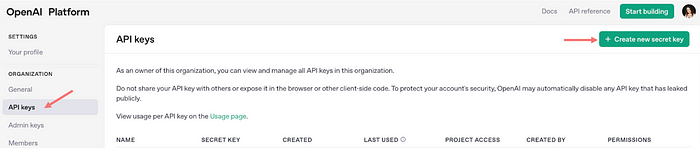
- Créer Compte Openai
- Accédez à la section «API Keys» et cliquez «Créez une nouvelle clé secrète.» Vous utiliserez cette clé plus tard pour authentifier vos demandes.
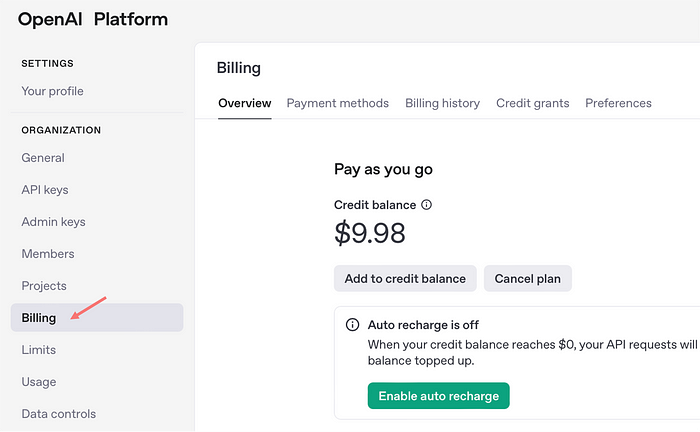
- Aller au Facturation Section et ajoutez des fonds à votre compte. L’ajout de 10 à 20 $ est suffisant pour commencer.
Vous êtes maintenant prêt à utiliser l’API.
Générer des affectations
Dans cette section, je vais montrer comment je génère des missions de devoirs à l’aide de Chatgpt.
Mais d’abord, un aperçu rapide de mon approche. J’enseigne l’analyse des données, et ma mission typique comprend un ensemble de données ainsi qu’un ensemble de questions larges et ouvertes à répondre aux étudiants. Ce format encourage la pensée critique et donne aux étudiants de la place à la créativité.
Pour générer chaque affectation, j’utilise:
- Matériaux de cours au format de présentation PDF
- UN ensemble de donnéesgénéralement au format CSV ou Excel
Sur la base de ces entrées, j’utilise Chatgpt pour créer la mission. Maintenant, permettez-moi de vous guider à travers le code.
Tout d’abord, importez toutes les bibliothèques nécessaires et insérez votre clé API à la section précédente.
import openai
import PyPDF2
import nbformatimport pandas as pd
openai.api_key = "YOUR_API_KEY_HERE"
Étant donné que l’affectation est basée sur des diapositives et des données de conférence PDF au format CSV, l’étape suivante consiste à charger ces fichiers et à extraire le texte. L’API ChatGPT fonctionne avec la entrée de texte, vous devez donc convertir tous les matériaux en texte brut avant de les envoyer.
Le code ci-dessous lit les présentations PDF. Gardez à l’esprit qu’il ne capture pas les graphiques ou les images. Cela n’a pas été un problème pour moi, mais selon le contenu avec lequel vous travaillez, cela pourrait être une limitation.
def extract_text_from_pdf(pdf_path):
text = ""
try:
with open(pdf_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
for page in reader.pages:
text += page.extract_text()
except Exception as e:
print(f"Error reading PDF: {e}")
return text
Si vous avez plusieurs présentations pour une seule affectation, vous pouvez les combiner en un seul bloc de texte.
combined_text = ""pdf_paths = ("Presentation1.pdf", "Presentation2.pdf")
for pdf_path in pdf_paths:
pdf_text = extract_text_from_pdf(pdf_path)
if pdf_text:
combined_text += pdf_text + "n"
Et préparez vos données à envoyer à Chatgpt.
data_path = 'data.csv'
csv_data = pd.read_csv(data_path)
csv_data_summary = csv_data.head(10).to_string()
Ensuite, créons une fonction qui envoie une demande à l’API Chatgpt.
def generate_homework(pdf_text, csv_data_summary, prompt):
full_prompt = (
f"{prompt}nn"
f"Presentation Content: {pdf_text(:10000)}nn"
f"Data:n{csv_data_summary}nn"
)try:
response = openai.chat.completions.create(
model='o3-mini', # "gpt-4o-mini"
messages=({"role": "user",
"content": full_prompt}),
temperature = 0.25
)
return response.choices(0).message.content
except Exception as e:
print(f"Error communicating with ChatGPT API: {e}")
return None
Voici comment cela fonctionne, étape par étape:
- La fonction prend votre conférence, un échantillon de l’ensemble de données et une invite (plus de détails sur l’invite dans la partie suivante).
- Il combine ensuite ces entrées dans un
full_prompt. - En tant que repli, je coupe le contenu de présentation à 10 000 caractères pour éviter de dépasser les limites d’entrée.
- Enfin, la fonction envoie l’invite à l’API ChatGPT. Vous pouvez utiliser différents modèles – j’utilise Gpt-4o mini pour cet exemple.
Maintenant, pour la partie la plus intéressante et la plus importante – l’invite. La qualité de la sortie dépend fortement de la façon dont vous expliquez vos instructions, donc cela vaut vraiment la peine de prendre le temps d’affiner vos invites.
Ci-dessous, je partagerai l’invite que j’utilise. Si vous avez des idées pour l’améliorer, n’hésitez pas à les partager dans les commentaires!
Dans mon invite, je:
- Demandez à Chatgpt de créer des questions ouvertes et d’encourager la narration, car je veux donner aux étudiants plus de place pour la créativité
- Fournir un exemple de question comme référence
- Demandez-lui clairement de se concentrer sur les matériaux de conférence pour éviter de générer des questions non pertinentes
prompt = """
I am a university professor teaching a course on data analytics and statistics using Python.I have a dataset with e-commerce transaction data. The dataset includes the following fields:
UserId, TransactionId, TransactionTime, ItemCode, ItemDescription, NumberOfItemPurchased, CostPerItem, Country.
I will upload a PDF containing the lecture materials.
Based on the concepts and materials covered in the lecture, please generate five assignment questions
for students working with this dataset.
The questions should:
- Be moderately open-ended (not too specific), to encourage critical thinking and analytical reasoning.
- Be clearly worded and suitable for university-level students.
- Encourage storytelling through data, not just coding.
- Align with topics from the lecture (e.g., data cleaning, descriptive statistics, visualizations,
group analysis, temporal trends).
Example (for reference):
“What can you tell about the distribution and descriptive statistics of the variables from the dataset?”
"""
Enfin, il est prêt à tout assembler.
result = generate_homework(combined_text, csv_data_summary, prompt)
Voici un exemple de la sortie que vous obtenez:
Here are five assignment questions designed to encourage critical thinking
and analytical reasoning while working with the e-commerce transaction dataset:1. **Descriptive Statistics and Customer Insights**:
"Using descriptive statistics, analyze the purchasing behavior of users in the dataset.
What insights can you draw about the average number of items purchased and the average cost per item?
Discuss how these metrics might vary across different countries and what implications this could have for marketing strategies."
2. **Temporal Trends Analysis**:
"Examine the transaction data over time. Identify any temporal trends in purchasing behavior,
such as seasonal spikes or declines in sales. How might these trends inform
inventory management and promotional strategies for the e-commerce platform?"
3. **Data Cleaning and Quality Assessment**:
"Reflect on the importance of data cleaning in your analysis.
Identify potential issues in the dataset (e.g., missing values, outliers) and propose
methods to address these issues. How might these data quality concerns impact your findings and the overall analysis?"
4. **Correlation and Customer Segmentation**:
"Investigate the relationship between the number of items purchased and the total cost of transactions.
What correlation do you observe, and what does it suggest about customer behavior?
Based on your findings, propose a segmentation strategy for targeting different customer groups."
5. **Visualization and Storytelling**:
"Create visualizations that effectively communicate key insights from the dataset.
Choose at least two different types of visualizations (e.g., histograms, bar charts, line graphs) to represent your findings.
How do these visualizations help tell the story of customer purchasing behavior, and what actionable insights can be derived from them?"
Dans mon cas, les résultats semblent assez bons. Je fais généralement des ajustements et supprime les instructions trop détaillées pour donner aux étudiants plus de liberté dans la façon dont ils abordent la mission.
Affectations de grade
Dans cette section, je vais expliquer comment je note les devoirs de devoirs en utilisant Chatgpt.
Juste pour récapituler: les étudiants reçoivent un ensemble de données et un ensemble de questions, et ils soumettent leurs réponses dans des cahiers Python, y compris des commentaires qui expliquent leur raisonnement.
Encore une fois, parcourons le code étape par étape.
Tout d’abord, les cahiers Python doivent être convertis en texte brut – tout comme je l’ai fait plus tôt avec les PDF.
def extract_notebook_content(notebook_path):
try:
with open(notebook_path, "r", encoding="utf-8") as file:
notebook = nbformat.read(file, as_version=4)content = ()
for cell in notebook.cells:
if cell.cell_type == "code":
content.append("### Code and comments:n" + cell.source.strip())
elif cell.cell_type == "markdown":
content.append("### Comments:n" + cell.source.strip())
return "nn".join(content)
except Exception as e:
print(f"Error reading notebook {notebook_path}: {e}")
return None
L’étape suivante consiste à préparer les soumissions des étudiants pour Chatgpt – mais cette partie s’est avérée plus difficile que prévu.
Au début, j’ai essayé d’évaluer le travail de chaque élève individuellement, mais Chatgpt a donné à presque toutes les notes similaires et j’ai eu du mal à distinguer les soumissions solides des plus faibles.
Pour résoudre ce problème, j’ai commencé à regrouper les soumissions en seaux d’environ cinq ans. J’ai divisé manuellement les étudiants en seaux pour m’assurer que les travaux de chaque seau étaient faciles à comparer. C’est une simple astuce qui a réellement fonctionné.
Un autre défi consiste à s’assurer que Chatgpt comprend clairement où le travail de chaque élève commence et se termine. Si cela n’est pas spécifié clairement, il peut sauter ou ignorer les soumissions de certains étudiants. Tous les noms utilisés sont fictifs, juste au cas où.
names = ("Clara", "Malik", "Sofia", "Evan", "Leila")notebook_contents = {}
for name in names:
notebook_contents(name) = extract_notebook_content(name+".ipynb")
Encore une fois, il existe une fonction pour envoyer une demande à l’API Chatgpt – c’est très similaire à celui décrit précédemment.
def generate_feedback(task_description, csv_data_summary, notebook_content, prompt):
full_prompt = (
f"Task Description: {task_description}nn"
f"Data:n{csv_data_summary}nn"
f"Student Notebook Content (Truncated):n{notebook_content}nn"
f"{prompt}nn"
) try:
response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=({"role": "user", "content": full_prompt}),
temperature = 0.25
)
return response.choices(0).message.content
except Exception as e:
print(f"Error communicating with ChatGPT API: {e}")
return None
Cette demande comprend:
- La description de la tâche (générée plus tôt, avec quelques petits ajustements)
- Un échantillon de l’ensemble de données (identique à la section précédente)
- Le contenu du cahier des étudiants, converti en texte brut
Voici la description de la tâche que j’utilise:
task_description = """
In this assignment, you're going to do customer analysis for e-commerce store. Data:
Transactions data for an e-commerce store. You'll find the dataset attached to the assignment.
Questions:
1. Identify potential issues in the dataset (e.g., missing values, outliers) and clean the data.
2. Using descriptive statistics, analyze the purchasing behavior of users in the dataset.
What insights can you draw about the average number of items purchased and the average cost per item?
Discuss how these metrics might vary across different countries and what implications this could have.
3. Examine the transaction data over time. Identify any temporal trends in purchasing behavior,
such as seasonal spikes or declines in sales.
4. Investigate the relationship between the number of items purchased and the total cost of transactions.
What correlation do you observe, and what does it suggest about customer behavior?
Format:
Submit Python notebook with interpretation of the results.
"""
Et comme auparavant, la partie la plus difficile est d’écrire l’invite.
Pour bien faire les choses, j’ai dû examiner moi-même plusieurs soumissions d’étudiants pour définir des critères clairs et identifier les erreurs courantes qui devraient entraîner des déductions ponctuelles. Cette étape est essentielle – vous devez être explicite sur le fonctionnement de l’évaluation afin que le chatppt puisse refléter votre logique.
Voici quelques stratégies rapides qui ont aidé:
- J’inclus des noms d’étudiants pour m’assurer que le chatppt ne saute accidentellement personne.
- Je fournis des instructions détaillées sur ce que les élèves sont censés faire (par exemple, nettoyer les valeurs aberrantes, traiter correctement les données, expliquer les résultats, etc.).
- Je définis des critères spécifiques pour les déductions ponctuelles – quelles erreurs à pénaliser et par combien.
Au début, j’ai remarqué que la même soumission des étudiants pouvait recevoir des notes très différentes chaque fois que je courais l’invite. J’ai réduit cette variabilité en rendant les critères d’évaluation plus clairs et les instructions plus structurées – mais une certaine variation se produit toujours.
Pour gérer cela, j’ai ajouté quelques éléments supplémentaires à l’invite:
- Je demande à Chatgpt de fournir son niveau de confiance Dans chaque grade. Si la confiance est faible ou moyenne, je passe en revue la soumission manuellement.
- Je demande également un justification de la note, je peux donc vérifier et revoir tout ce qui semble éteint.
Vous pouvez également utiliser la partie finale – les justifications de grade – pour repérer les erreurs courantes les étudiants commettent et leur résoudre dans les futures conférences.
Voici la version finale de l’invite que j’utilise. Si vous avez des suggestions pour l’améliorer, je serais heureux de les entendre!
prompt = """
You are a university professor evaluating student assignments.
You will receive submissions from several students in the following format:
- Each student’s work starts with: "WORK OF START"
- And ends with: "WORK OF END"The students are: Clara, Malik, Sofia, Evan, Leila
Assignment requirements:
Students need to:
- Remove outliers from the dataset
- Aggregate data by customer
- Calculate and interpret mean, median, and variance for all variables
- Analyze correlation coefficients
- Provide descriptive statistics by country
Students must interpret and explain their results (e.g., significance of descriptive statistics,
meaning of correlations, behavior differences by country).
Grading criteria:
- Maximum is 10 points
- Deduct 2 points: No explanations for statistics, correlations, or behavior differences
- Deduct 1 point: Outliers not removed
- Deduct 2 points: Data not aggregated by customer
- Deduct 2 points for each unanswered question
- Deduct 4 points: no description or insights provided
- Give 1 extra point: Extra analysis (e.g., statistical tests, clustering)
Instructions:
For each student, give:
- Name
- Final grade and your level of confidence in this grade.
- 5 concise bullet points justifying the grade (max total: 500 characters)
After assigning the grade, re-check the instructions and adjust the grade if needed.
Be strict, fair, and brief.
"""
Voici un exemple de ce à quoi ressemblent les résultats.
### Student: Clara
- **Final Grade:** 6/10 (Confidence: Medium)
- **Justifications:**
- Outliers were removed appropriately.
- Data was aggregated by customer.
- Mean, median, and variance were calculated, but explanations were insufficient.
- Correlation coefficients were analyzed, but interpretations were lacking.
- Descriptive statistics were provided, but comparisons across countries were incomplete.
Réflexions finales
Allons tout résumer. Voici mes principaux plats à retenir:
- Générer des affectations de devoirs s’avère être assez simple et facile à commencer.
- GradationCependant, prend plus d’efforts si vous voulez que Chatgpt produise des résultats cohérents et fiables.
Quelques conseils pratiques:
- Passez en revue plusieurs soumissions d’étudiants pour définir des critères d’évaluation clairs – ce que vous voulez voir et ce qui mérite une déduction
- Les soumissions de groupe en petits lots et garantir que chaque lot contient des soumissions avec des niveaux de qualité clairement différents. Cela aide à mieux évaluer et à faire la différence entre eux.
Je passe toujours en revue les soumissions et ajuste les notes en cas de besoin, mais Chatgpt aide vraiment à rationaliser le processus.
Merci d’avoir lu! J’espère que vous l’avez trouvé utile. Si vous avez des questions ou des commentaires, n’hésitez pas à les partager ci-dessous – je serai heureux d’en discuter.
Publié via Vers l’IA
Source link



