
Créer des pipelines ETL pour les flux de travail de la science des données dans environ 30 lignes de Python
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 12 minutes de lecture

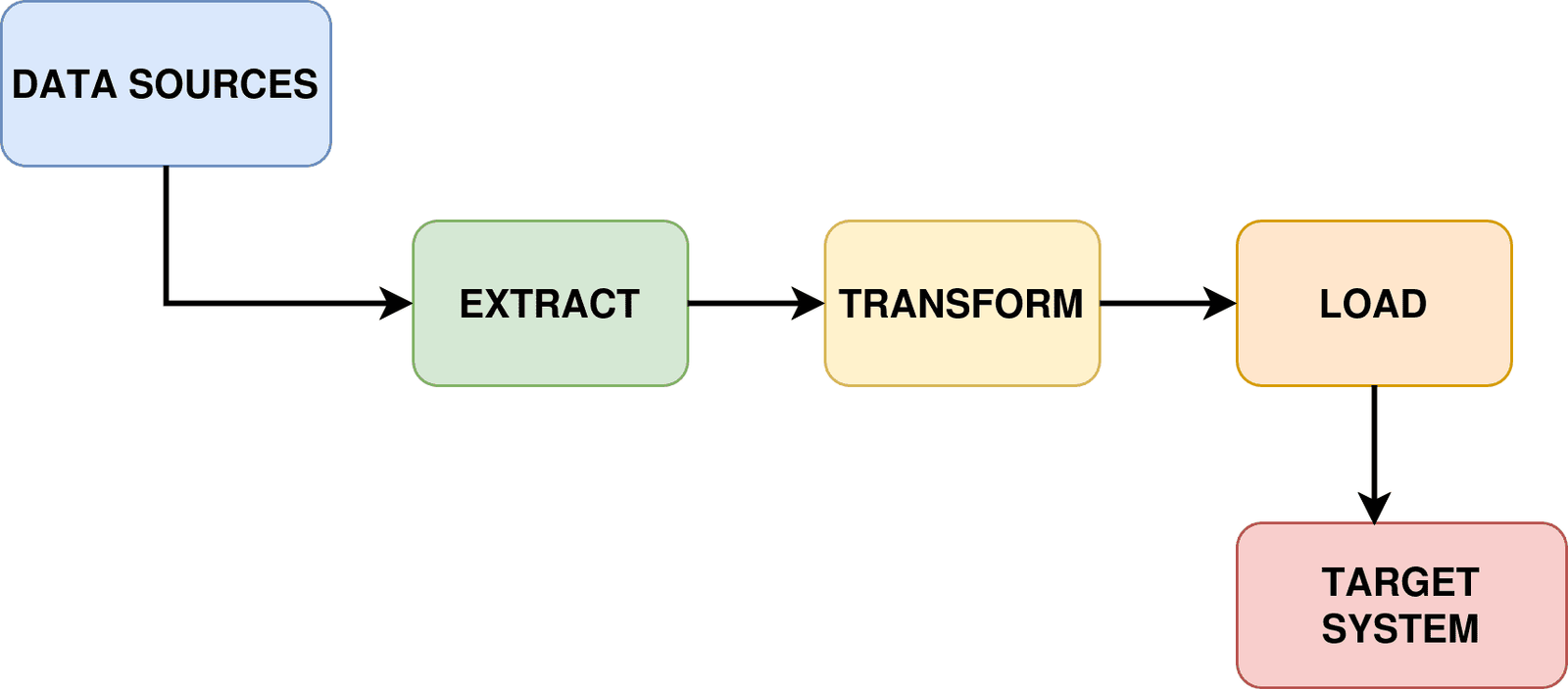

Image de l’auteur | Idéogramme
Vous connaissez ce sentiment lorsque vous avez des données dispersées dans différents formats et sources, et que vous devez donner un sens à tout cela? C’est exactement ce que nous résolvons aujourd’hui. Construisons un pipeline ETL qui prend des données désordonnées et les transforme en quelque chose d’utile.
Dans cet article, je vous guiderai à travers la création d’un pipeline qui traite les transactions de commerce électronique. Rien d’extraordinaire, juste du code pratique qui fait le travail.
Nous allons récupérer les données d’un fichier CSV (comme vous le téléchargez à partir d’une plate-forme de commerce électronique), le nettoyer et le stocker dans une base de données appropriée pour l’analyse.
🔗 Lien vers le code sur github
Qu’est-ce qu’un pipeline d’extrait, de transformation, de charge (ETL)?
Chaque pipeline ETL suit le même schéma. Vous prenez des données quelque part (extraire), nettoyez-la et améliorez-la (transformée), puis mettez-la quelque part utile (charge).
Pipeline ETL | Image de l’auteur | diagrams.net (draw.io)
Le processus commence par le extrait Phase, où les données sont récupérées à partir de divers systèmes source tels que des bases de données, des API, des fichiers ou des plates-formes de streaming. Au cours de cette phase, le pipeline identifie et tire les données pertinentes tout en conservant des connexions à des systèmes disparates qui peuvent fonctionner sur différents horaires et formats.
Ensuite le transformer La phase représente l’étape de traitement du noyau, où les données extraites subissent le nettoyage, la validation et la restructuration. Cette étape aborde les problèmes de qualité des données, applique les règles métier, effectue des calculs et convertit les données en format et structure requis. Les transformations communes incluent les conversions de types de données, la cartographie des champs, les agrégations et la suppression des doublons ou des enregistrements non valides.
Enfin, le charger La phase transfère les données désormais transformées en système cible. Cette étape peut se produire par des charges complètes, où des ensembles de données entiers sont remplacés, ou des charges incrémentielles, où seules des données nouvelles ou modifiées sont ajoutées. La stratégie de chargement dépend de facteurs tels que le volume des données, les exigences de performance du système et les besoins de l’entreprise.
Étape 1: extraire
L’étape «Extraire» est l’endroit où nous mettons la main sur les données. Dans le monde réel, vous pourriez télécharger ce CSV à partir du tableau de bord de reportage de votre plate-forme électronique, de le tirer à partir d’un serveur FTP ou de l’obtenir via l’API. Ici, nous lisons à partir d’un fichier CSV disponible.
def extract_data_from_csv(csv_file_path):
try:
print(f"Extracting data from {csv_file_path}...")
df = pd.read_csv(csv_file_path)
print(f"Successfully extracted {len(df)} records")
return df
except FileNotFoundError:
print(f"Error: {csv_file_path} not found. Creating sample data...")
csv_file = create_sample_csv_data()
return pd.read_csv(csv_file)
Maintenant que nous avons les données brutes de sa source (raw_transactions.csv), nous devons le transformer en quelque chose d’utilisation.
Étape 2: Transformer
C’est là que nous rendons les données réellement utiles.
def transform_data(df):
print("Transforming data...")
df_clean = df.copy()
# Remove records with missing emails
initial_count = len(df_clean)
df_clean = df_clean.dropna(subset=('customer_email'))
removed_count = initial_count - len(df_clean)
print(f"Removed {removed_count} records with missing emails")
# Calculate derived fields
df_clean('total_amount') = df_clean('price') * df_clean('quantity')
# Extract date components
df_clean('transaction_date') = pd.to_datetime(df_clean('transaction_date'))
df_clean('year') = df_clean('transaction_date').dt.year
df_clean('month') = df_clean('transaction_date').dt.month
df_clean('day_of_week') = df_clean('transaction_date').dt.day_name()
# Create customer segments
df_clean('customer_segment') = pd.cut(df_clean('total_amount'),
bins=(0, 50, 200, float('inf')),
labels=('Low', 'Medium', 'High'))
return df_clean
Tout d’abord, nous supprimons les lignes avec des e-mails manquants car les données client incomplètes ne sont pas utiles pour la plupart des analyses.
Ensuite, nous calculons total_amount en multipliant le prix et la quantité. Cela semble évident, mais vous seriez surpris de la fréquence à laquelle des champs dérivés sont manquants dans les données brutes.
L’extraction de date est vraiment pratique. Au lieu d’avoir un horodatage, nous avons maintenant des colonnes séparées de l’année, du mois et du jour de la semaine. Cela facilite l’analyse des modèles tels que « venons-nous plus le week-end? »
La segmentation du client en utilisant pd.cut() peut être particulièrement utile. Il pose automatiquement les clients dans les catégories de dépenses. Maintenant, au lieu d’avoir simplement des montants de transaction, nous avons des segments d’entreprise significatifs.
Étape 3: chargement
Dans un vrai projet, vous pourriez être chargé dans une base de données, envoyer à une API ou pousser vers le stockage cloud.
Ici, nous chargeons nos données propres dans une base de données SQLite appropriée.
def load_data_to_sqlite(df, db_name="ecommerce_data.db", table_name="transactions"):
print(f"Loading data to SQLite database '{db_name}'...")
conn = sqlite3.connect(db_name)
try:
df.to_sql(table_name, conn, if_exists="replace", index=False)
cursor = conn.cursor()
cursor.execute(f"SELECT COUNT(*) FROM {table_name}")
record_count = cursor.fetchone()(0)
print(f"Successfully loaded {record_count} records to '{table_name}' table")
return f"Data successfully loaded to {db_name}"
finally:
conn.close()
Maintenant, les analystes peuvent exécuter des requêtes SQL, connecter des outils BI et utiliser ces données pour la prise de décision.
SQLite fonctionne bien pour cela car il est léger, ne nécessite aucune configuration et crée un seul fichier que vous pouvez facilement partager ou sauvegarder. Le if_exists="replace" Le paramètre signifie que vous pouvez exécuter ce pipeline plusieurs fois sans vous soucier des données en double.
Nous avons ajouté des étapes de vérification afin que vous sachiez que la charge a réussi. Il n’y a rien de pire que de penser que vos données sont stockées en toute sécurité uniquement pour trouver une table vide plus tard.
Exécution du pipeline ETL
Cela orchestre l’ensemble de l’extrait, transforme, chargez le flux de travail.
def run_etl_pipeline():
print("Starting ETL Pipeline...")
# Extract
raw_data = extract_data_from_csv('raw_transactions.csv')
# Transform
transformed_data = transform_data(raw_data)
# Load
load_result = load_data_to_sqlite(transformed_data)
print("ETL Pipeline completed successfully!")
return transformed_data
Remarquez comment cela relie tout ensemble. Extraire, transformer, charger, faire. Vous pouvez exécuter ceci et voir immédiatement vos données traitées.
Vous pouvez trouver le code complet sur github.
Emballage
Ce pipeline prend des données de transaction brutes et les transforme en quelque chose avec lequel un analyste ou un scientifique des données peut réellement travailler. Vous avez des enregistrements propres, des champs calculés et des segments significatifs.
Chaque fonction fait bien une chose et vous pouvez facilement modifier ou étendre n’importe quelle pièce sans casser le reste.
Maintenant, essayez de le faire fonctionner vous-même. Essayez également de le modifier pour un autre cas d’utilisation. Codage heureux!
Bala Priya C est développeur et écrivain technique d’Inde. Elle aime travailler à l’intersection des mathématiques, de la programmation, de la science des données et de la création de contenu. Ses domaines d’intérêt et d’expertise incluent DevOps, la science des données et le traitement du langage naturel. Elle aime lire, écrire, coder et café! Actuellement, elle travaille sur l’apprentissage et le partage de ses connaissances avec la communauté des développeurs en créant des tutoriels, des guides pratiques, des pièces d’opinion, etc. Bala crée également des aperçus de ressources engageants et des tutoriels de codage.
Source link



