
7 erreurs que les scientifiques font lors de la demande d’emplois
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 14 minutes de lecture

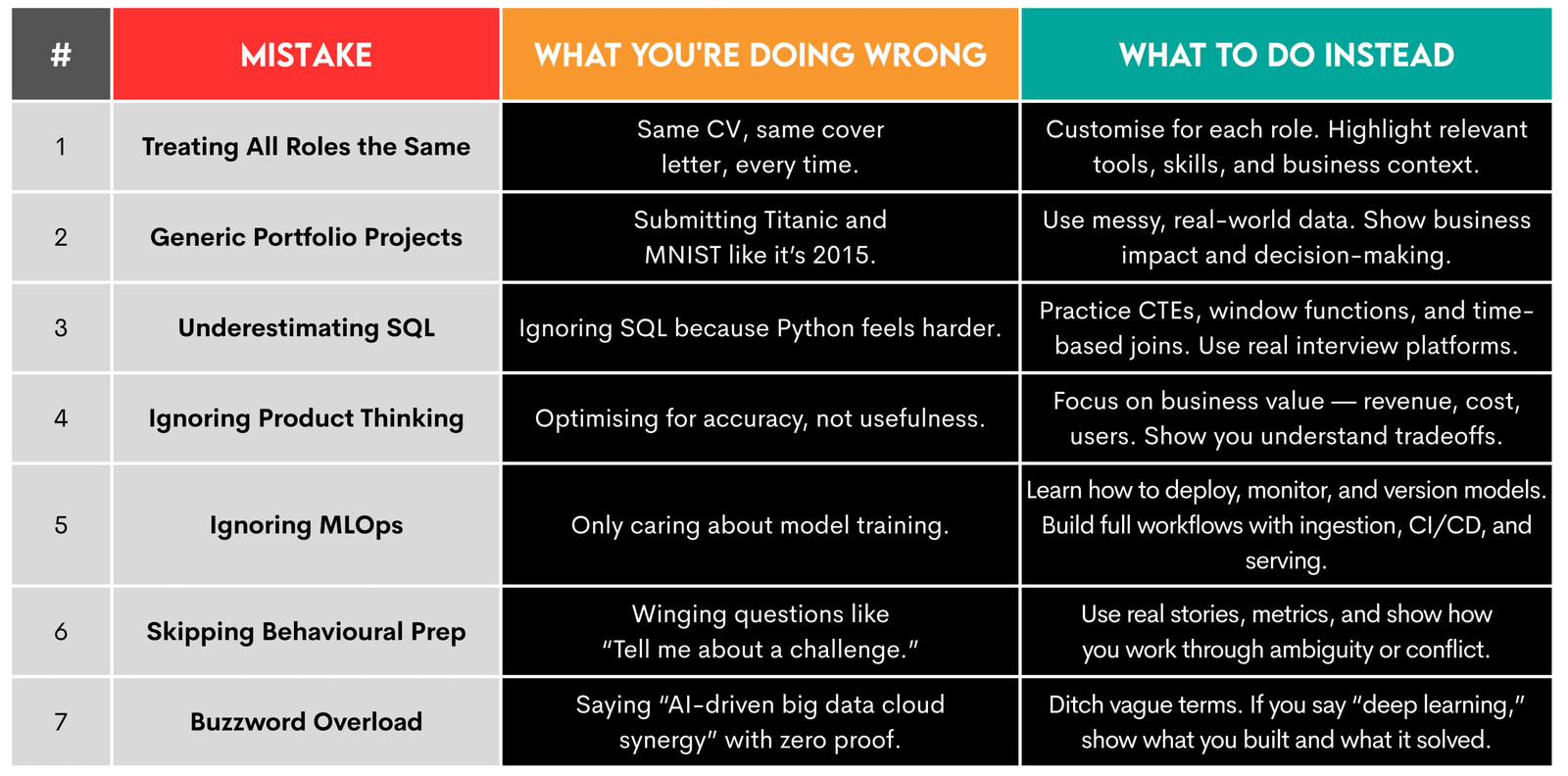

Image de l’auteur | Toile
Le marché du travail des sciences des données est bondé. Les employeurs et les recruteurs sont parfois de vrais trous qui vous fantômes juste quand vous pensiez commencer à négocier votre salaire.
Comme si vous combattiez vos concurrents, vos recruteurs et les employeurs ne suffit pas, vous devez également vous battre. Parfois, le manque de succès lors des entretiens concerne vraiment les scientifiques des données. Faire des erreurs est acceptable. Ne pas apprendre d’eux est tout sauf!
Alors, disséquons quelques erreurs courantes et voyons comment ne pas les faire lors de la demande d’un emploi de science des données.
1. Traiter tous les rôles de la même manière
Erreur: Envoi du même curriculum vitae et lettre de motivation à chaque rôle que vous postulez, des postes de recherche et des postes de contrôle du client, à un cuisinier ou à un sosie de Timothee Chalamet.
Pourquoi ça fait mal: Parce que vous voulez le travail, pas le «meilleur candidat global pour tous les postes pour lesquels nous n’embauchons pas». Les entreprises veulent que vous vous intégriez dans le travail particulier.
Un rôle dans une startup logicielle pourrait prioriser l’analyse des produits, tandis qu’une compagnie d’assurance recrute pour la modélisation dans R.
Pas Adapter votre Le CV et la lettre de motivation pour vous présenter comme très adaptés à un poste comportent un risque d’être négligé avant même l’entretien.
Une solution:
- Lisez attentivement la description du poste.
- Adaptez votre CV et votre lettre de motivation aux exigences du travail mentionnées – compétences, outils et tâches.
- Ne vous contentez pas d’énumérer les compétences, mais montrez votre expérience avec les applications pertinentes de ces compétences.
2. Projets de données génériques trop génériques
Erreur: Soumettre un portefeuille de projets de données débordant de projets lavés comme Titanic, des ensembles de données IRIS, une MNIST ou une prédiction des prix des maisons.
Pourquoi ça fait mal: Parce que les recruteurs s’endormiront lorsqu’ils liront votre candidature. Ils ont vu les mêmes portefeuilles des milliers de fois. Ils vous ignoreront, car ce portefeuille ne montre que votre manque de pensée commerciale et de créativité.
Une solution:
- Travaillez avec des données désordonnées et réelles. Sourcez les projets et les données de sites tels que Stratascratch, Se gêner, Datasf, Datahub par NYC Open Data, Ensembles de données publiques impressionnantesetc.
- Travailler sur des projets moins communs
- Choisissez des projets qui montrent vos passions et résolvent des problèmes commerciaux pratiques, idéalement ceux que votre employeur pourrait avoir.
- Expliquez les compromis et pourquoi votre approche a du sens dans un contexte commercial.
3. Sous-estimation SQL
Erreur: Ne pratiquez pas assez SQL, car «c’est facile par rapport au python ou à l’apprentissage automatique».
Pourquoi ça fait mal: Parce que connaître Python et comment éviter le sur-ajustement ne fait pas de vous un expert SQL. Oh, oui, SQL est également fortement testé, en particulier pour les rôles de science des données de l’analyste et de niveau intermédiaire. Les entretiens se concentrent souvent davantage sur SQL que Python.
Une solution:
- Pratiquez des concepts SQL complexes: sous-questionnaires, CTES, fonctions de fenêtre, jointures de séries chronologiques, pivotage et requêtes récursives.
- Utiliser des plateformes comme Stratascratch et Leetcode pour pratiquer les questions d’entrevue SQL du monde réel.
4. Ignorer la pensée des produits
Erreur: Se concentrer sur les métriques du modèle au lieu de la valeur commerciale.
Pourquoi ça fait mal: Parce qu’un modèle qui prédit le désabonnement des clients avec 94% Roc-aUcmais surtout des signaux de signalement des clients qui n’utilisent plus le produit, n’ont aucune valeur commerciale. Vous ne pouvez pas conserver des clients qui ont déjà disparu. Vos compétences n’existent pas dans le vide; Les employeurs veulent que vous utilisiez ces compétences pour offrir de la valeur.
Une solution:
5. Ignorer les Mlops
Erreur: Se concentrer uniquement sur la création d’un modèle tout en ignorant son déploiement, son suivi, son réglage fin et comment il fonctionne en production.
Pourquoi ça fait mal: Parce que vous pouvez coller votre modèle, vous savez où il n’est pas utilisable en production. La plupart des employeurs ne vous considéreront pas comme un candidat sérieux si vous ne savez pas comment votre modèle est déployé, recyclé ou surveillé. Vous ne ferez pas nécessairement tout cela par vous-même. Mais vous devrez montrer des connaissances, car vous travaillerez avec des ingénieurs d’apprentissage automatique pour vous assurer que votre modèle fonctionne réellement.
Une solution:
- Comprendre les trois principales façons de informatique: traitement par lots, en temps réel et hybride.
- Comprendre pipelines d’apprentissage automatique, CI / CDet Surveillance du modèle d’apprentissage automatique.
- Pratiquez la conception du flux de travail dans vos projets en incluant ingestion de donnéesmodèle entraînement, versioninget portion.
- Familiez-vous avec les outils d’orchestration d’apprentissage automatique, tels que Préfet et Flux d’air (pour l’orchestration), Kubeflow et Zenml (pour l’abstraction du pipeline), et Mlflow et Poids et préjugés (pour le suivi).
6. Être non préparé aux questions d’entrevue comportementale
Erreur: Broupez des questions telles que «Parlez-moi d’un défi que vous avez été confronté» comme non important et ne vous préparez pas.
Pourquoi ça fait mal: Ces questions ne font pas partie de l’interview (seulement) parce que l’intervieweur s’ennuie à mort avec sa vie de famille, donc elle préfère s’asseoir avec vous dans un bureau étouffant posant des questions stupides. Les questions comportementales testent comment vous pensez et communiquez.
Une solution:
7. Utilisation de mots à la mode sans contexte
Erreur: Emballer votre CV avec des mots à la mode techniques et commerciaux, mais pas d’exemples concrètes.
Pourquoi ça fait mal: Parce que «les synergies de Big Data à effet de pointe pour rationaliser la solution IA axée sur les données évolutive pour l’intelligence générative de bout en bout dans le cloud» ne signifie vraiment rien. Vous pourriez accidentellement impressionner quelqu’un avec cela. (Mais ne comptez pas là-dessus.) Plus souvent, on vous demandera d’expliquer ce que vous entendez par cela et risquez d’admettre que vous n’avez aucune idée de ce dont vous parlez.
Réparez-le:
- Évitez d’utiliser des mots à la mode et communiquer clairement.
- Sachez de quoi vous parlez. Si vous ne pouvez pas éviter d’utiliser des mots à la mode, pour chaque mot à la mode, incluez une phrase qui montre comment vous l’avez utilisé et pourquoi.
- Ne soyez pas vague. Au lieu de dire «j’ai de l’expérience avec DL», dis «j’ai utilisé Mémoire à court terme pour prévoir la demande de produits et réduire les stocks de 24% ».
Conclusion
Éviter ces sept erreurs n’est pas difficile. Les faire peut être coûteux, alors ne les faites pas. Le processus de recrutement en science des données est suffisamment compliqué et horrible. Essayez de ne pas vous compliquer encore la vie en succombant aux mêmes erreurs stupides que les autres scientifiques des données.
Nate Rosidi est un scientifique des données et en stratégie de produit. Il est également professeur auxiliaire qui enseigne l’analyse et est le fondateur de Stratascratch, une plate-forme aidant les scientifiques des données à se préparer à leurs entretiens avec de véritables questions d’entrevue de grandes entreprises. Nate écrit sur les dernières tendances du marché de la carrière, donne des conseils d’entrevue, partage des projets de science des données et couvre tout SQL.
Source link



