
Automatiser les rapports de qualité des données avec N8N: du CSV à l’analyse professionnelle
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 19 minutes de lecture
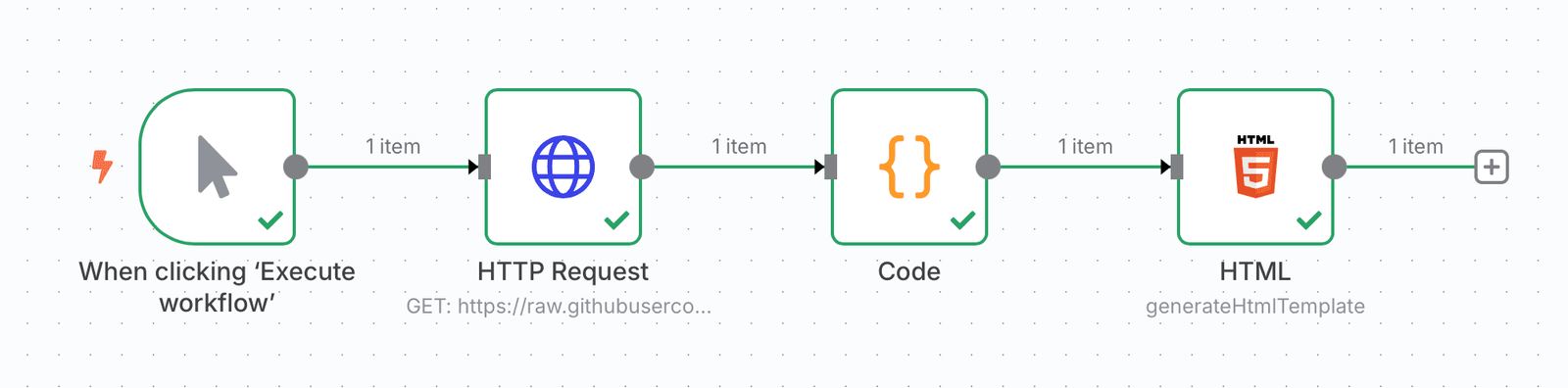
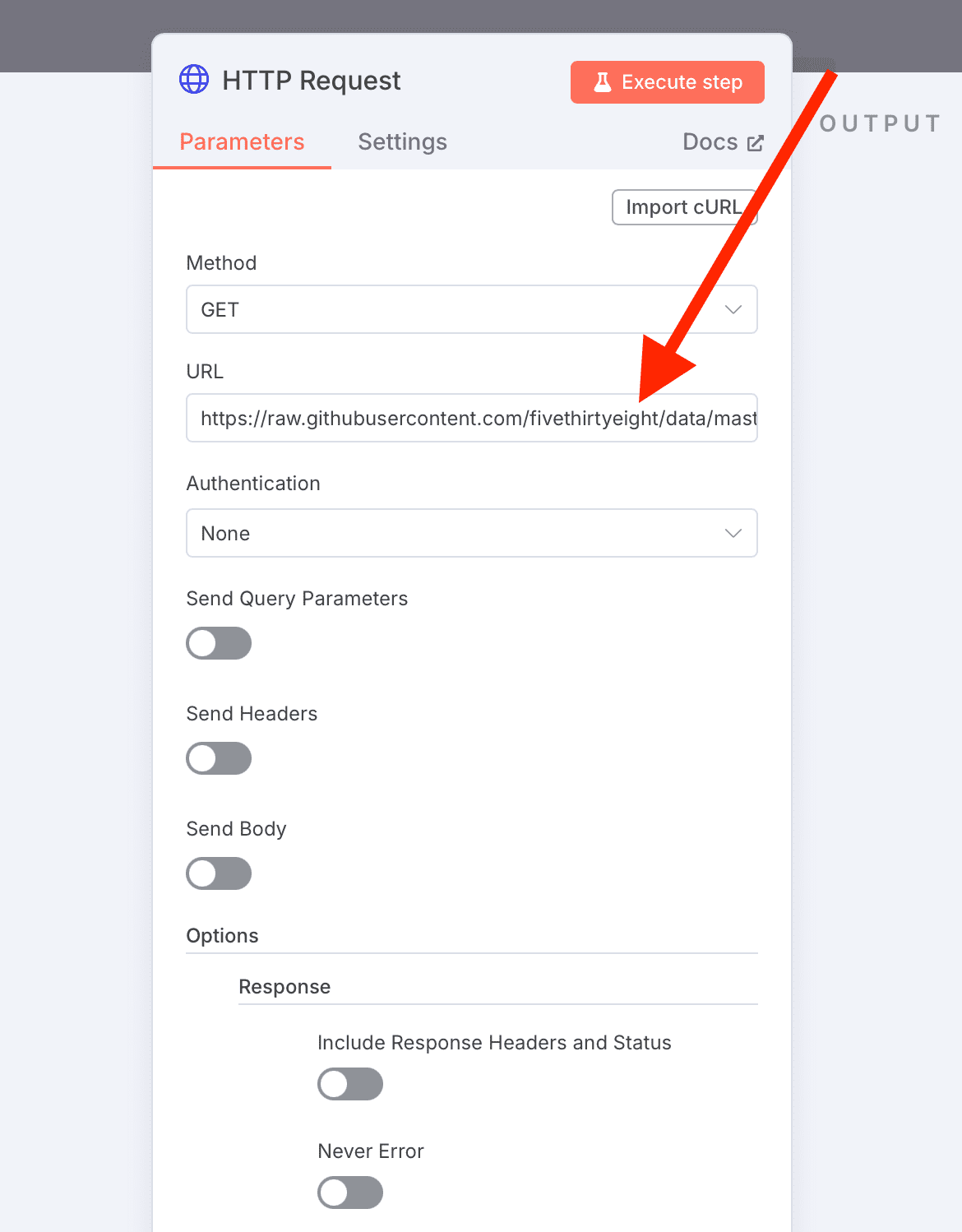
Image de l’auteur | Chatte
Le goulot d’étranglement de la qualité des données est
Vous venez de recevoir un nouvel ensemble de données. Avant de plonger dans l’analyse, vous devez comprendre avec quoi vous travaillez: combien de valeurs manquantes? Quelles colonnes sont problématiques? Quel est le score global de qualité des données?
La plupart des scientifiques des données passent 15 à 30 minutes à explorer manuellement chaque nouvel ensemble de données, en les déchargeant en pandas, en fonctionnant .info(), .describe()et .isnull().sum()puis créant des visualisations pour comprendre les modèles de données manquants. Cette routine devient fastidieuse lorsque vous évaluez quotidiennement plusieurs ensembles de données.
Et si vous pouviez coller une URL CSV et obtenir un rapport de qualité de données professionnelles en moins de 30 secondes? Aucune configuration d’environnement Python, pas de codage manuel, pas de commutation entre les outils.
La solution: un flux de travail N8N à 4 nœuds
N8N (prononcé « n-eight-n ») est une plate-forme d’automatisation de workflow open-source qui connecte différents services, API et outils via une interface visuelle, glisser-déposer. Alors que la plupart des gens associent l’automatisation du flux de travail à des processus métier comme le marketing par e-mail ou le support client, N8N peut également aider à automatiser les tâches de science des données qui nécessitent traditionnellement des scripts personnalisés.
Contrairement à l’écriture de scripts Python autonome, les flux de travail N8N sont visuels, réutilisables et faciles à modifier. Vous pouvez connecter des sources de données, effectuer des transformations, exécuter des analyses et fournir des résultats, tous sans basculer entre différents outils ou environnements. Chaque flux de travail se compose de « nœuds » qui représentent différentes actions, connectées ensemble pour créer un pipeline automatisé.
Notre analyseur automatisé de qualité de données se compose de quatre nœuds connectés:
- Déclencheur manuel – démarre le workflow lorsque vous cliquez sur « Exécuter »
- Demande HTTP – récupère n’importe quel fichier CSV à partir d’une URL
- Noeud de code – Analyse les données et génère des mesures de qualité
- Nœud html – Crée un beau rapport professionnel
Construire le flux de travail: implémentation étape par étape
Condition préalable
- Compte N8N (essai gratuit de 14 jours à n8n.io)
- Notre modèle de flux de travail prédéfini (Fichier JSON fourni)
- Tout ensemble de données CSV accessible via URL public (nous fournirons des exemples de test)
Étape 1: Importez le modèle de flux de travail
Plutôt que de construire à partir de zéro, nous utiliserons un modèle préconfiguré qui inclut toute la logique d’analyse:
- Télécharger le fichier de workflow
- Open N8N et cliquez sur « Importer à partir du fichier »
- Sélectionnez le fichier JSON téléchargé – Les quatre nœuds apparaîtront automatiquement
- Enregistrer le workflow avec votre nom préféré
Le flux de travail importé contient quatre nœuds connectés avec tous les code d’analyse et d’analyse complexes déjà configurés.
Étape 2: Comprendre votre flux de travail
Passons à ce que fait chaque nœud:
Node de déclenchement manuel: Démarre l’analyse lorsque vous cliquez sur « Exécuter le flux de travail ». Parfait pour les vérifications de qualité des données à la demande.
Node de demande HTTP: Rechet les données CSV de toute URL publique. Pré-configuré pour gérer la plupart des formats CSV standard et renvoyer les données de texte brutes nécessaires à l’analyse.
Noeud de code: Le moteur d’analyse qui comprend une logique d’analyse CSV robuste pour gérer les variations courantes de l’utilisation du délimiteur, des champs cités et des formats de valeur manquants. Il est automatiquement:
- Parses Données CSV avec détection de champ intelligente
- Identifie les valeurs manquantes en plusieurs formats (nul, vide, « n / a », etc.)
- Calcule des scores de qualité et des cotes de gravité
- Génère des recommandations spécifiques et exploitables
Nœud html: Transforme les résultats de l’analyse en un beau rapport professionnel avec des scores de qualité codés en couleur et une mise en forme propre.
Étape 3: Personnalisation de vos données
Pour analyser votre propre ensemble de données:
- Cliquez sur le nœud de demande HTTP
- Remplacer l’URL avec votre URL de l’ensemble de données CSV:
- Actuel:
https://raw.githubusercontent.com/fivethirtyeight/data/master/college-majors/recent-grads.csv - Vos données:
https://your-domain.com/your-dataset.csv
- Actuel:
- Enregistrer le workflow
C’est ça! La logique d’analyse s’adapte automatiquement à différentes structures CSV, noms de colonnes et types de données.
Étape 4: Exécutez et affichez les résultats
- Cliquez sur « Exécuter le workflow » Dans la barre d’outils supérieure
- Regardez le processus des nœuds – chacun affichera une coche verte une fois terminé
- Cliquez sur le nœud HTML et sélectionnez l’onglet « HTML » pour afficher votre rapport
- Copiez le rapport ou prenez des captures d’écran à partager avec votre équipe
L’ensemble du processus prend moins de 30 secondes une fois votre flux de travail configuré.
Comprendre les résultats
Le score de qualité à code couleur vous donne une évaluation immédiate de votre ensemble de données:
- 95-100%: Qualité de données parfaite (ou presque parfaite), prête à une analyse immédiate
- 85-94%: Excellente qualité avec un nettoyage minimal nécessaire
- 75-84%: Bonne qualité, un certain prétraitement requis
- 60-74%: Une qualité équitable, un nettoyage modéré nécessaire
- En dessous de 60%: Mauvaise qualité, travail de données significatif requis
Remarque: Cette implémentation utilise un système de notation simple basé sur les données manquantes. Des métriques de qualité avancées comme la cohérence des données, la détection des valeurs aberrantes ou la validation du schéma pourraient être ajoutées aux versions futures.
Voici à quoi ressemble le rapport final:
Notre exemple d’analyse montre un score de qualité de 99,42% – indiquant que l’ensemble de données est largement complet et prêt à analyser avec un minimum de prétraitement.
Présentation de l’ensemble de données:
- 173 Records totaux: Une taille d’échantillon petite mais suffisante idéale pour une analyse exploratoire rapide
- 21 colonnes totales: Un nombre gérable de fonctionnalités qui permettent des informations ciblées
- 4 colonnes avec des données manquantes: Quelques champs sélectionnés contiennent des lacunes
- 17 colonnes complètes: La majorité des champs sont entièrement peuplés
Test avec différents ensembles de données
Pour voir comment le flux de travail gère variant les modèles de qualité des données, essayez ces exemples de données:
- Ensemble de données iris (
https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv) montre généralement un score parfait (100%) sans valeurs manquantes. - Ensemble de données titanic (
https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv) démontre un score plus réaliste de 67,6% en raison de données manquantes stratégiques dans des colonnes comme l’âge et la cabine. - Vos propres données: Téléchargez sur GitHub brut ou utilisez une URL CSV publique
En fonction de votre score de qualité, vous pouvez déterminer les prochaines étapes: au-dessus de 95% signifie directement à l’analyse des données exploratoires, 85-94% suggère que le nettoyage minimal des colonnes problématiques identifiées, 75-84%, indique un travail de prétraitement modéré, 60 à 74% nécessite une planification des stratégies de nettoyage ciblées pour plusieurs colonnes, et moins de 60% de suggestions d’évaluation si le jeu de données est adapté à vos objectifs de données significatifs. Le flux de travail s’adapte automatiquement à toute structure CSV, vous permettant d’évaluer rapidement plusieurs ensembles de données et de hiérarchiser vos efforts de préparation des données.
Étapes suivantes
1. Intégration par e-mail
Ajouter un Envoyer un e-mail Node pour livrer automatiquement des rapports aux parties prenantes en le connectant après le nœud HTML. Cela transforme votre flux de travail en un système de distribution où les rapports de qualité sont automatiquement envoyés aux chefs de projet, aux ingénieurs de données ou aux clients chaque fois que vous analysez un nouvel ensemble de données. Vous pouvez personnaliser le modèle de messagerie pour inclure des résumés exécutifs ou des recommandations spécifiques en fonction du score de qualité.
2. Analyse planifiée
Remplacez le déclencheur manuel par un Déclencheur du calendrier Pour analyser automatiquement les ensembles de données à intervalles réguliers, parfait pour surveiller les sources de données qui mettent à jour fréquemment. Configurez les vérifications quotidiennes, hebdomadaires ou mensuelles de vos ensembles de données clés pour assister tôt à la dégradation de la qualité. Cette approche proactive vous aide à identifier les problèmes de pipeline de données avant qu’ils ne affectent l’analyse en aval ou les performances du modèle.
3. Analyse de l’ensemble de données multiples
Modifiez le workflow pour accepter une liste des URL CSV et générer simultanément un rapport de qualité comparatif sur plusieurs ensembles de données. Cette approche de traitement par lots est inestimable lors de l’évaluation des sources de données pour un nouveau projet ou de la réalisation d’audits réguliers dans l’inventaire de données de votre organisation. Vous pouvez créer des tableaux de bord récapitulatifs qui classent les ensembles de données par Score de qualité, en aidant à hiérarchiser les sources de données nécessitant une attention immédiate par rapport à celles prête à analyser.
4. Différents formats de fichiers
Étendez le flux de travail pour gérer d’autres formats de données au-delà de CSV en modifiant la logique d’analyse dans le nœud de code. Pour les fichiers JSON, adaptez l’extraction de données pour gérer les structures et les tableaux imbriquées, tandis que les fichiers Excel peuvent être traités en ajoutant une étape de prétraitement pour convertir XLSX au format CSV. La prise en charge de plusieurs formats fait de votre analyseur de qualité un outil universel pour toute source de données dans votre organisation, quelle que soit la façon dont les données sont stockées ou livrées.
Conclusion
Ce flux de travail N8N montre comment l’automatisation visuelle peut rationaliser les tâches de science des données de routine tout en conservant la profondeur technique dont les données des données ont besoin. En tirant parti de votre arrière-plan de codage existant, vous pouvez personnaliser la logique d’analyse JavaScript, étendre les modèles de rapports HTML et vous intégrer à votre infrastructure de données préférée – le tout dans une interface visuelle intuitive.
La conception modulaire du flux de travail le rend particulièrement précieux pour les scientifiques des données qui comprennent à la fois les exigences techniques et le contexte commercial de l’évaluation de la qualité des données. Contrairement aux outils rigides sans code, N8N vous permet de modifier la logique d’analyse sous-jacente tout en fournissant une clarté visuelle qui rend les flux de travail faciles à partager, à déboguer et à maintenir. Vous pouvez commencer par cette fondation et ajouter progressivement des fonctionnalités sophistiquées telles que la détection des anomalies statistiques, les mesures de qualité personnalisées ou l’intégration avec votre pipeline MOLPS existant.
Plus important encore, cette approche comble le fossé entre l’expertise en science des données et l’accessibilité organisationnelle. Vos collègues techniques peuvent modifier le code tandis que les parties prenantes non techniques peuvent exécuter des workflows et interpréter immédiatement les résultats. Cette combinaison de sophistication technique et d’exécution conviviale rend le N8N idéal pour les scientifiques des données qui souhaitent évoluer leur impact au-delà de l’analyse individuelle.
Né en Inde et élevé au Japon, Vinod apporte une perspective mondiale à l’enseignement des sciences des données et de l’apprentissage automatique. Il comble le fossé entre les technologies émergentes de l’IA et la mise en œuvre pratique des professionnels du travail. Vinod se concentre sur la création de voies d’apprentissage accessibles pour des sujets complexes tels que l’IA agentique, l’optimisation des performances et l’ingénierie de l’IA. Il se concentre sur les implémentations pratiques de l’apprentissage automatique et le mentorat de la prochaine génération de professionnels des données grâce à des sessions en direct et à des conseils personnalisés.
Source link



