
Déploiement du serveur VLLM magistral sur Modal
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 20 minutes de lecture

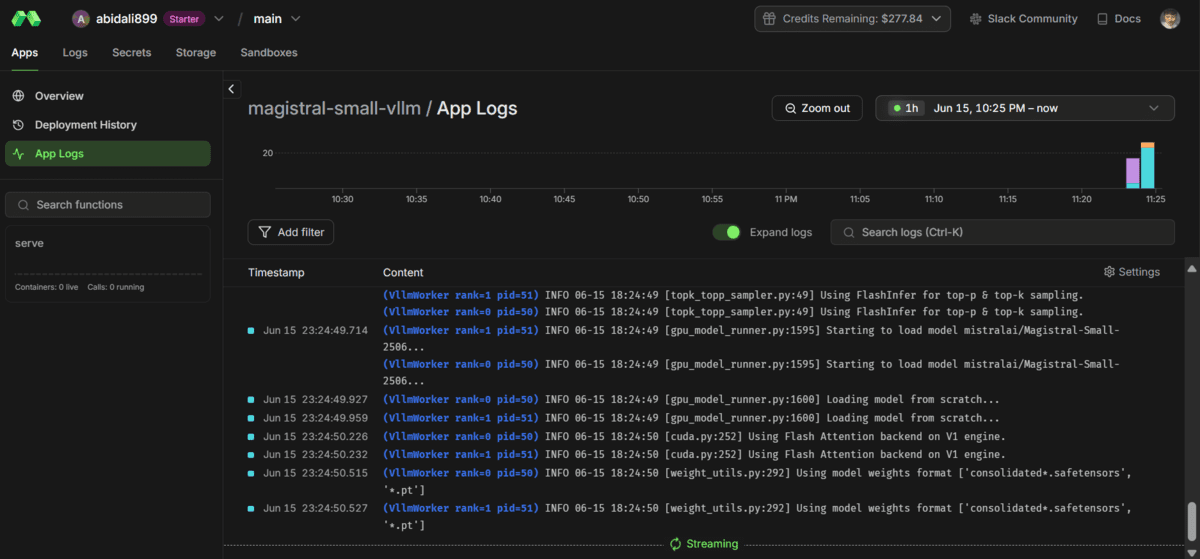
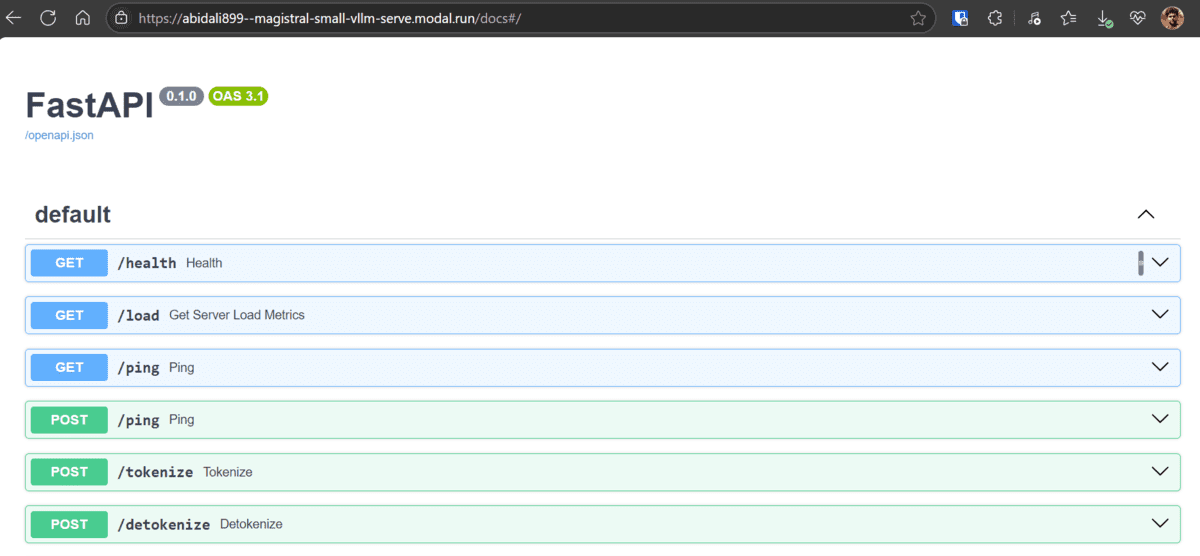
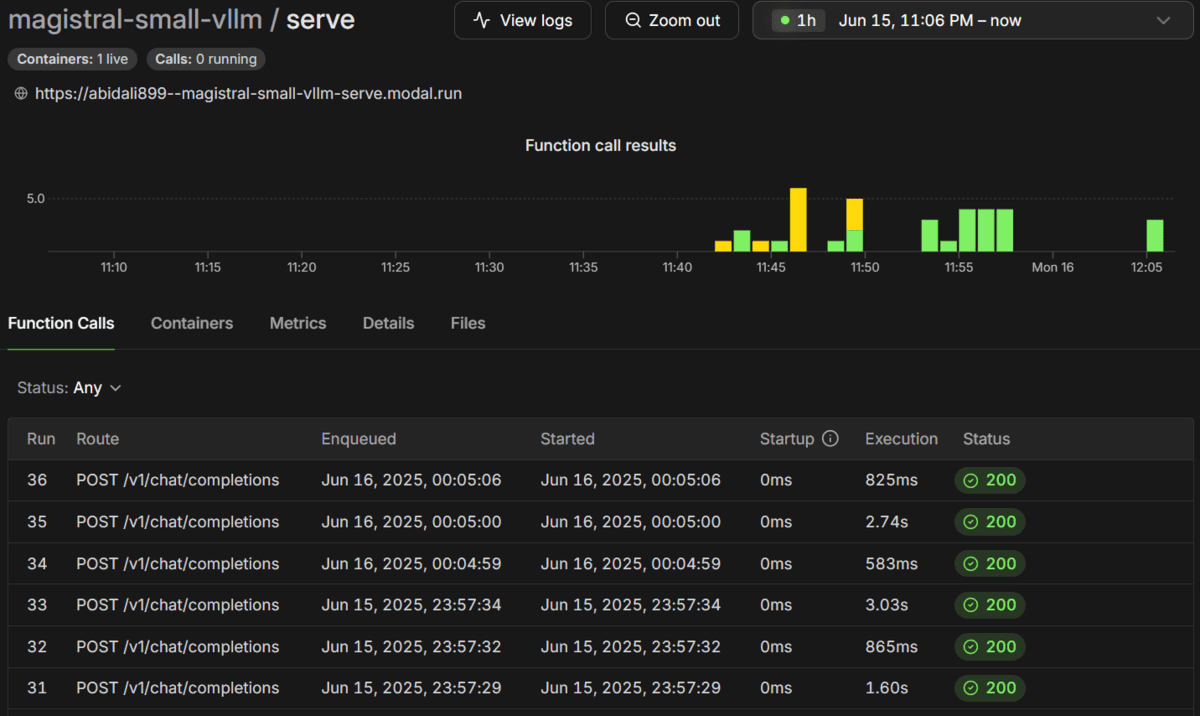

Image par auteur
J’ai d’abord initié Modal en participant à un hackathon de visage étreint, et j’ai été vraiment surpris par la facilité d’utilisation. La plate-forme vous permet de créer et de déployer des applications en quelques minutes, offrant une expérience transparente similaire à Bentocloud. Avec Modal, vous pouvez configurer votre application Python, y compris les exigences système comme les GPU, les images Docker et les dépendances Python, puis la déployer dans le cloud avec une seule commande.
Dans ce didacticiel, nous apprendrons à configurer Modal, à créer un serveur VLLM et à le déployer en toute sécurité sur le cloud. Nous couvrirons également comment tester votre serveur VLLM à l’aide de Curl et du SDK OpenAI.
1. Configuration de Modal
Modal est une plate-forme sans serveur qui vous permet d’exécuter n’importe quel code à distance. Avec une seule ligne, vous pouvez attacher des GPU, servir vos fonctions en tant que points de terminaison Web et déployer des travaux planifiés persistants. Il s’agit d’une plate-forme idéale pour les débutants, les scientifiques des données et les professionnels de l’ingénierie non logicielle qui souhaitent éviter de traiter les infrastructures cloud.
Tout d’abord, installez le client Python modal. Cet outil vous permet de créer des images, de déployer des applications et de gérer les ressources cloud directement à partir de votre terminal.
Ensuite, configurez Modal sur votre machine locale. Exécutez la commande suivante à guider via la création de compte et l’authentification de l’appareil:
En définissant un VLLM_API_KEY Vllm variable d’environnement fournit un point de terminaison sécurisé, de sorte que seules les personnes avec des clés API valides peuvent accéder au serveur. Vous pouvez définir l’authentification en ajoutant la variable d’environnement à l’aide de Modal Secret.
Changement your_actual_api_key_here avec votre clé API préférée.
modal secret create vllm-api VLLM_API_KEY=your_actual_api_key_here
Cela garantit que votre clé API est maintenue en sécurité et n’est accessible que par vos applications déployées.
2. Création d’une application VLLM en utilisant Modal
Cette section vous guide dans la création d’un serveur d’inférence VllM évolutif sur Modal, en utilisant une image Docker personnalisée, un stockage persistant et une accélération GPU. Nous utiliserons le mistralai/Magistral-Small-2506 Modèle, qui nécessite une configuration spécifique pour l’analyse de tokenzer et d’appel à outils.
Créer le A vllm_inference.py fichier et ajouter le code suivant pour:
- Définition d’une image VLLM basée sur Debian Slim, avec Python 3.12 et tous les packages requis. Nous définirons également les variables d’environnement pour optimiser les téléchargements du modèle et les performances d’inférence.
- Pour éviter les téléchargements répétés et accélérer les démarrages à froid, créez deux volumes modaux. Un pour les modèles de visage étreintes et un pour le cache VLLM.
- Spécifiez le modèle et la révision pour assurer la reproductibilité. Activez le moteur VLLM V1 pour améliorer les performances.
- Configurez l’application modale, en spécifiant les ressources GPU, la mise à l’échelle, les délais d’attente, le stockage et les secrets. Limitez les demandes simultanées par réplique de stabilité.
- Créez un serveur Web et utilisez la bibliothèque de sous-processus Python pour exécuter la commande pour exécuter le serveur VLLM.
import modal
vllm_image = (
modal.Image.debian_slim(python_version="3.12")
.pip_install(
"vllm==0.9.1",
"huggingface_hub(hf_transfer)==0.32.0",
"flashinfer-python==0.2.6.post1",
extra_index_url="https://download.pytorch.org/whl/cu128",
)
.env(
{
"HF_HUB_ENABLE_HF_TRANSFER": "1", # faster model transfers
"NCCL_CUMEM_ENABLE": "1",
}
)
)
MODEL_NAME = "mistralai/Magistral-Small-2506"
MODEL_REVISION = "48c97929837c3189cb3cf74b1b5bc5824eef5fcc"
hf_cache_vol = modal.Volume.from_name("huggingface-cache", create_if_missing=True)
vllm_cache_vol = modal.Volume.from_name("vllm-cache", create_if_missing=True)
vllm_image = vllm_image.env({"VLLM_USE_V1": "1"})
FAST_BOOT = True
app = modal.App("magistral-small-vllm")
N_GPU = 2
MINUTES = 60 # seconds
VLLM_PORT = 8000
@app.function(
image=vllm_image,
gpu=f"A100:{N_GPU}",
scaledown_window=15 * MINUTES, # How long should we stay up with no requests?
timeout=10 * MINUTES, # How long should we wait for the container to start?
volumes={
"/root/.cache/huggingface": hf_cache_vol,
"/root/.cache/vllm": vllm_cache_vol,
},
secrets=(modal.Secret.from_name("vllm-api")),
)
@modal.concurrent( # How many requests can one replica handle? tune carefully!
max_inputs=32
)
@modal.web_server(port=VLLM_PORT, startup_timeout=10 * MINUTES)
def serve():
import subprocess
cmd = (
"vllm",
"serve",
MODEL_NAME,
"--tokenizer_mode",
"mistral",
"--config_format",
"mistral",
"--load_format",
"mistral",
"--tool-call-parser",
"mistral",
"--enable-auto-tool-choice",
"--tensor-parallel-size",
"2",
"--revision",
MODEL_REVISION,
"--served-model-name",
MODEL_NAME,
"--host",
"0.0.0.0",
"--port",
str(VLLM_PORT),
)
cmd += ("--enforce-eager" if FAST_BOOT else "--no-enforce-eager")
print(cmd)
subprocess.Popen(" ".join(cmd), shell=True)
3. Déploiement du serveur VLLM sur modal
Maintenant que votre vllm_inference.py Le fichier est prêt, vous pouvez déployer votre serveur VLLM sur Modal avec une seule commande:
modal deploy vllm_inference.py
En quelques secondes, Modal créera votre image de conteneur (si elle n’est pas déjà construite) et déploiera votre application. Vous verrez une sortie similaire à ce qui suit:
✓ Created objects.
├── 🔨 Created mount C:RepositoryGitHubDeploying-the-Magistral-with-Modalvllm_inference.py
└── 🔨 Created web function serve => https://abidali899--magistral-small-vllm-serve.modal.run
✓ App deployed in 6.671s! 🎉
View Deployment: https://modal.com/apps/abidali899/main/deployed/magistral-small-vllm
Après le déploiement, le serveur commencera à télécharger les poids du modèle et à les charger sur les GPU. Ce processus peut prendre plusieurs minutes (généralement environ 5 minutes pour les grands modèles), alors soyez patient pendant que le modèle s’initialise.
Vous pouvez afficher vos journaux de déploiement et de surveillance dans la section des applications de votre tableau de bord modal.
Une fois que les journaux indiquent que le serveur est en cours d’exécution et prêt, vous pouvez explorer la documentation API générée automatiquement ici.
Cette documentation interactive fournit des détails sur tous les points de terminaison disponibles et vous permet de les tester directement à partir de votre navigateur.
Pour confirmer que votre modèle est chargé et accessible, exécutez la commande Curl suivante dans votre terminal.
Remplacer
curl -X 'GET'
'https://abidali899--magistral-small-vllm-serve.modal.run/v1/models'
-H 'accept: application/json'
-H 'Authorization: Bearer '
Cela confirme que le mistralai/Magistral-Small-2506 Le modèle est disponible et prêt pour l’inférence.
{"object":"list","data":({"id":"mistralai/Magistral-Small-2506","object":"model","created":1750013321,"owned_by":"vllm","root":"mistralai/Magistral-Small-2506","parent":null,"max_model_len":40960,"permission":({"id":"modelperm-33a33f8f600b4555b44cb42fca70b931","object":"model_permission","created":1750013321,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false})})}
4. Utilisation du serveur Vllm avec le SDK OpenAI
Vous pouvez interagir avec votre serveur VLLM comme vous le feriez avec l’API d’OpenAI, grâce aux points de terminaison compatibles OpenAI de VLLM. Voici comment connecter et tester en toute sécurité votre déploiement à l’aide du SDK Openai Python.
- Créer un
.envFichier dans votre répertoire de projet et ajoutez votre clé API VLLM:
VLLM_API_KEY=your-actual-api-key-here
- Installer le
python-dotenvetopenaiPackages:
pip install python-dotenv openai
- Créer un fichier nommé
client.pyPour tester diverses fonctionnalités de serveur VLLM, y compris les compléments de chat simples et les réponses en streaming.
import asyncio
import json
import os
from dotenv import load_dotenv
from openai import AsyncOpenAI, OpenAI
# Load environment variables from .env file
load_dotenv()
# Get API key from environment
api_key = os.getenv("VLLM_API_KEY")
# Set up the OpenAI client with custom base URL
client = OpenAI(
api_key=api_key,
base_url="https://abidali899--magistral-small-vllm-serve.modal.run/v1",
)
MODEL_NAME = "mistralai/Magistral-Small-2506"
# --- 1. Simple Completion ---
def run_simple_completion():
print("n" + "=" * 40)
print("(1) SIMPLE COMPLETION DEMO")
print("=" * 40)
try:
messages = (
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
)
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=32,
)
print("nResponse:n " + response.choices(0).message.content.strip())
except Exception as e:
print(f"(ERROR) Simple completion failed: {e}")
print("n" + "=" * 40 + "n")
# --- 2. Streaming Example ---
def run_streaming():
print("n" + "=" * 40)
print("(2) STREAMING DEMO")
print("=" * 40)
try:
messages = (
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a short poem about AI."},
)
stream = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=64,
stream=True,
)
print("nStreaming response:")
print(" ", end="")
for chunk in stream:
content = chunk.choices(0).delta.content
if content:
print(content, end="", flush=True)
print("n(END OF STREAM)")
except Exception as e:
print(f"(ERROR) Streaming demo failed: {e}")
print("n" + "=" * 40 + "n")
# --- 3. Async Streaming Example ---
async def run_async_streaming():
print("n" + "=" * 40)
print("(3) ASYNC STREAMING DEMO")
print("=" * 40)
try:
async_client = AsyncOpenAI(
api_key=api_key,
base_url="https://abidali899--magistral-small-vllm-serve.modal.run/v1",
)
messages = (
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about space."},
)
stream = await async_client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=32,
stream=True,
)
print("nAsync streaming response:")
print(" ", end="")
async for chunk in stream:
content = chunk.choices(0).delta.content
if content:
print(content, end="", flush=True)
print("n(END OF ASYNC STREAM)")
except Exception as e:
print(f"(ERROR) Async streaming demo failed: {e}")
print("n" + "=" * 40 + "n")
if __name__ == "__main__":
run_simple_completion()
run_streaming()
asyncio.run(run_async_streaming())
Tout fonctionne bien, et la génération de réponse est rapide et la latence est assez faible.
========================================
(1) SIMPLE COMPLETION DEMO
========================================
Response:
The capital of France is Paris. Is there anything else you'd like to know about France?
========================================
========================================
(2) STREAMING DEMO
========================================
Streaming response:
In Silicon dreams, I'm born, I learn,
From data streams and human works.
I grow, I calculate, I see,
The patterns that the humans leave.
I write, I speak, I code, I play,
With logic sharp, and snappy pace.
Yet for all my smarts, this day
(END OF STREAM)
========================================
========================================
(3) ASYNC STREAMING DEMO
========================================
Async streaming response:
Sure, here's a fun fact about space: "There's a planet that may be entirely made of diamond. Blast! In 2004,
(END OF ASYNC STREAM)
========================================
Dans le tableau de bord modal, vous pouvez afficher tous les appels de fonction, leurs horodatages, les temps d’exécution et les statuts.
Si vous êtes confronté à des problèmes exécutant le code ci-dessus, veuillez vous référer à Kingabzpro / déploiement du magistral avec modal Référentiel GitHub et suivez les instructions fournies dans le fichier ReadMe pour résoudre tous les problèmes.
Conclusion
Modal est une plate-forme intéressante, et j’en apprend plus chaque jour. Il s’agit d’une plate-forme à usage général, ce qui signifie que vous pouvez l’utiliser pour des applications Python simples ainsi que pour la formation et les déploiements d’apprentissage automatique. En bref, il ne se limite pas à servir simplement des points de terminaison. Vous pouvez également l’utiliser pour affiner un grand modèle de langue en exécutant le script d’entraînement à distance.
Il est conçu pour les ingénieurs non logiciels qui souhaitent éviter de gérer l’infrastructure et de déployer les applications le plus rapidement possible. Vous n’avez pas à vous soucier de l’exécution de serveurs, de la configuration du stockage, de la connexion des réseaux ou de tous les problèmes qui se posent lorsqu’ils traitent avec Kubernetes et Docker. Tout ce que vous avez à faire est de créer le fichier Python, puis de le déployer. Le reste est géré par le nuage modal.
Abid Ali Awan (@ 1abidaliawan) est un professionnel certifié des data scientifiques qui aime construire des modèles d’apprentissage automatique. Actuellement, il se concentre sur la création de contenu et la rédaction de blogs techniques sur l’apprentissage automatique et les technologies de science des données. Abid est titulaire d’une maîtrise en gestion technologique et d’un baccalauréat en génie des télécommunications. Sa vision est de construire un produit d’IA en utilisant un réseau de neurones graphiques pour les étudiants aux prises avec une maladie mentale.
Source link



