
(R) Analyser les chemins de données des chemins de données traversent l’espace latent en cluster avec LLMS
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 4 minutes de lecture
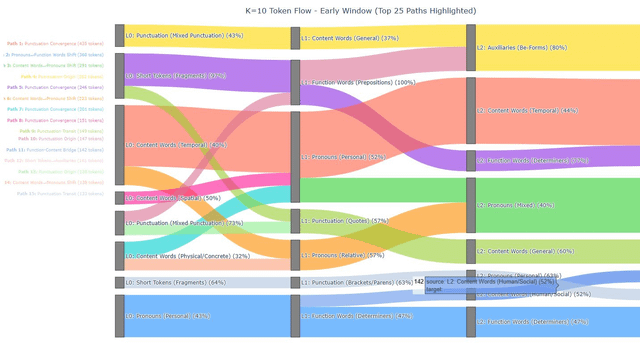
|
Bonjour, Je suis un chercheur indépendant qui a des problèmes pour faire sortir un signal. Je veux aussi obtenir des commentaires sur mon travail, je suis loin d’être un expert, mais je pense que c’est intéressant. Fondamentalement, mon approche consiste à utiliser différentes approches de clustering pour cluster les «vecteurs d’activation» dans différentes couches d’un NN, puis suivre les chemins différents points de données empruntent à travers ces grappes. Nous nous soucions davantage de la façon dont le NN organise la population, il s’agit donc d’une approche géométrique plutôt que d’un seul poids individuel. La plus grande innovation dans mon esprit est vraiment l’utilisation de LLMS pour étiqueter les clusters en fonction de la population, puis avec cette analyse et étiqueter les différents points de données des voies communes (les chemins archétypaux). Quoi qu’il en soit, voici une image montrant une expérience qui traçait les «jetons individuels» via GPT2 (fenêtre précoce). Remarque Au bas, les pronoms sont divisés en «contenu humain / social» et «déterminants fonctionnels» en bas (les scores de pureté sémantique montrent le pourcentage de jetons sur ce chemin qui est de cette catégorie). C’est quelque peu arbitraire car je suis en train de suivre les jetons individuels et de nombreux pronoms peuvent être les deux. Le suivant consiste à montrer comment une deuxième intégration transférerait le routage d’un chemin vers l’autre (nous avons une métrique de notation de décalage de cluster). Quoi qu’il en soit, voici mon article: https://drive.google.com/file/d/1abxxkcsaajvwborjpg6arhdro4xrzama/view?usp=sharing Les principaux problèmes théoriquement dont nous parlons quelque peu dans le journal. Le premier K-Means est une heuristique, il nous donnera donc une lentille accidentée. C’est OK – les astronomes sont très bien avec des lentilles rugueuses, mais nous voulons trouver une approche «géométriquement» pour le regroupement dans l’espace latent. J’explore le regroupement hiérchical pour décomposer des grappes plus grandes en microclustres, une similitude explicable de la maintenance qui est une nouvelle mesure de distance qui a plus de sens par rapport à l’Euclidien et autres, puis tout simplement des tests rigoureux du regroupement – pouvons-nous extraire des règles de ces voies qui correspondent aux systèmes d’experts, pouvons-nous reproduire des clusters sur différentes graines, etc. Faites-moi savoir ce que vous pensez! soumis par / u / royalspecialist1777 |




{kind=link}