
Pourquoi le sur-ajustement se produit et comment la régularisation le corrige (avec L1 & L2 expliqué simplement) | par Kushagra Pandya | Juin 2025
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 6 minutes de lecture
Maître sur-ajustement et régularisation avec Python
Lire ici pour GRATUIT
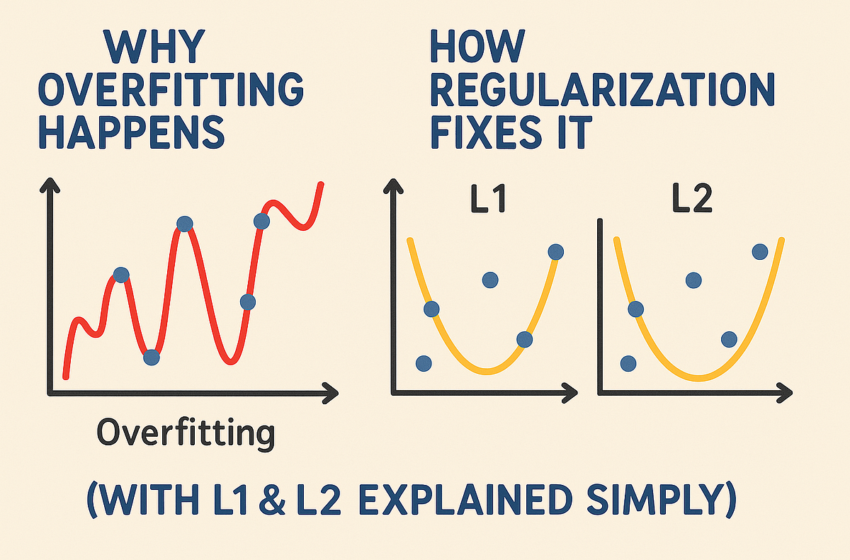
Le sur-ajustement est un piège à apprentissage automatique où un modèle excelle sur les données de formation mais flops sur des données invisibles, comme la mémorisation de réponses au lieu d’apprentissage des concepts. La régularisation, avec des techniques telles que L1 et L2, apprivagne à cela en encourageant des modèles plus simples. Ce guide de ~ 7 minutes explore pourquoi le sur-ajustement se produit, comment la régularisation de L1 et L2 l’empêche, et des analogies intuitives, avec du code Python pour un ensemble de données de prédiction des prix des maisons (taille, chambres, âge). Parfait pour les débutants et les pros, démystifions le sur-ajustement!
Le sur-ajustement se produit lorsqu’un modèle mémorise les données de formation, y compris le bruit, au lieu d’apprendre des modèles généraux. Comme un étudiant entassant les réponses à l’examen exact, il échoue lorsque les questions changent légèrement.
Signes:
- Erreur de formation faible, erreur de test / validation élevée.
- Modèles complexes avec de nombreux paramètres.
- Les prédictions se balancent sauvagement avec de petits changements d’entrée.
Exemple: Prédire les prix des maisons à partir de la taille, des chambres et de l’âge, un modèle de surfiance pourrait mémoriser les bizarreries (par exemple, le prix de la maison d’une maison spécifique) plutôt que…



