
Alors, votre application LLM fonctionne … mais est-ce fiable? (D)
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 4 minutes de lecture
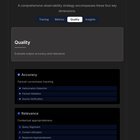
|
Quelqu’un d’autre trouve que la construction d’applications LLM fiables implique de gérer une complexité importante et un comportement imprévisible? Il semble que l’ère où les vérifications de base de la disponibilité et de la latence suffisaient sont en grande partie derrière nous pour ces systèmes. Désormais, l’accent inclut nécessairement le suivi de la qualité de la réponse, la détection des hallucinations avant d’avoir un impact sur les utilisateurs et la gestion efficace des coûts de jetons – des préoccupations opérationnelles clés pour la production de la production. A eu une discussion productive sur l’observabilité de LLM avec le CTO du Traceloop l’autre Wweek. Le message central était qu’une observabilité robuste nécessite plusieurs couches. Tracé (pour comprendre le cycle de vie complet de la demande), Métrique (pour quantifier les performances, les coûts et les erreurs), Qualité / Eval Évaluation (évaluant de manière critique la validité et la pertinence de la réponse), et Connaissances (Comment transformer ces informations en action et comment elle change notre architecture?) Naturellement, ce besoin a conduit à un paysage à croissance rapide d’outils spécialisés. J’ai en fait créé un diagramme de comparaison utile tentant de cartographier cet espace (couvrant des options comme Traceloop, Langsmith, Langfuse, Arize, Datadog, etc.). C’est assez dense. Le partage de ces points comme perspective pourrait être utile pour que d’autres naviguent dans l’espace LLMOPS. J’espère que cette perspective est utile. soumis par / u / oba2311 |




{kind=link}