
(D) La distillation est sous-estimée. J’ai reproduit la capacité de GPT-4O dans un modèle 14x moins cher
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 2 minutes de lecture
|
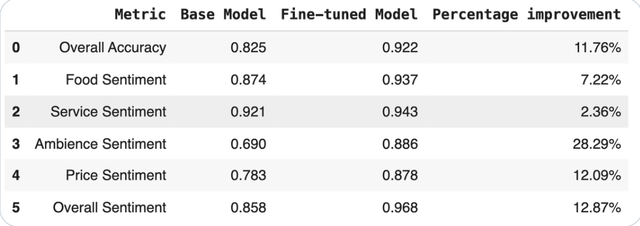
Je viens d’essayer quelque chose de cool avec la distillation. A réussi à reproduire les performances de niveau GPT-4o (précision à 92%) en utilisant un modèle beaucoup plus petit et affiné et il fonctionne 14x moins cher. Pour ceux qui ne sont pas familiers, la distillation est essentiellement: prenez un modèle énorme et coûteux et utilisez-le pour entraîner un plus petit, moins cher et plus rapide sur un domaine spécifique. Si cela est bien fait, le petit modèle pourrait fonctionner presque De plus, à une fraction du coût. Honnêtement, super prometteur. Curieux si quelqu’un d’autre ici a joué avec la distillation. Dites-moi plus de cas d’utilisation. Ajout de mon code dans les commentaires. soumis par / u / ambitieux_anybody855 |




{kind=link}