
7 DuckDB SQL Queries qui vous sauvent des heures de travail de pandas
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 34 minutes de lecture

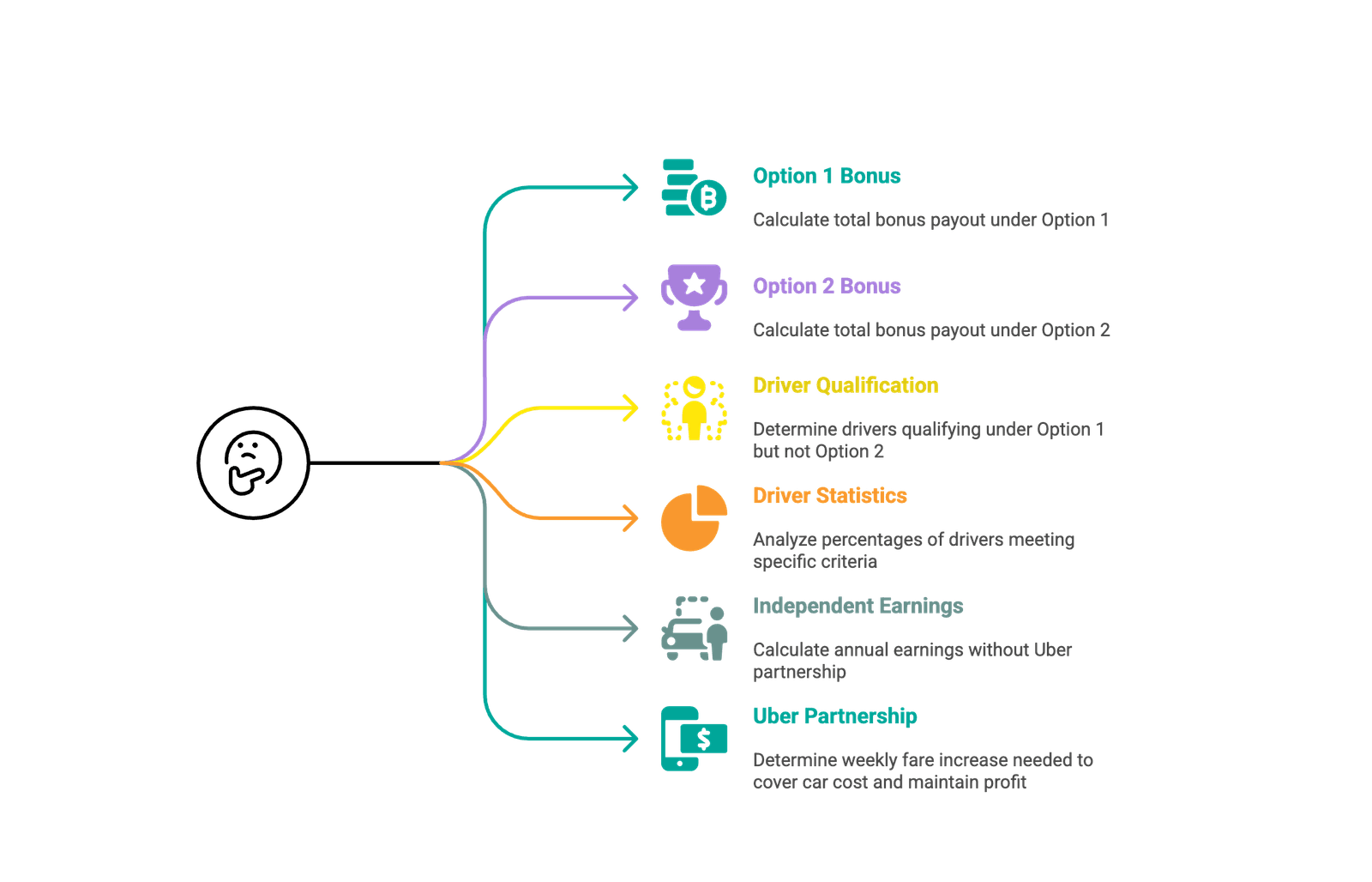

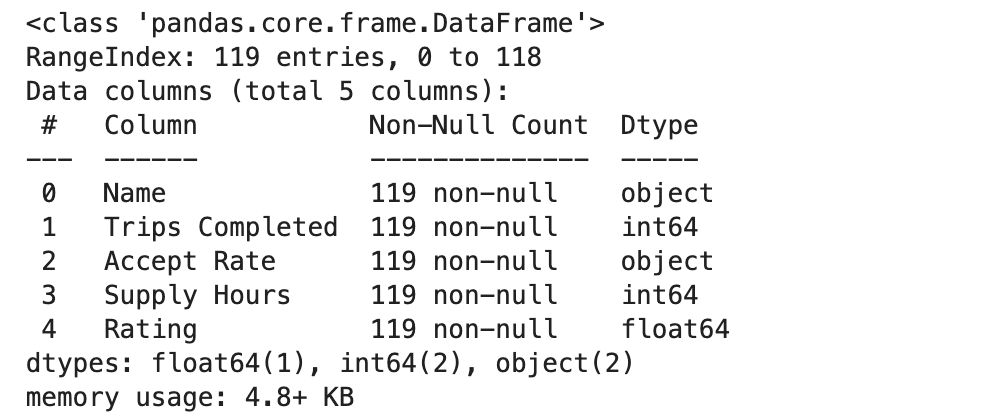



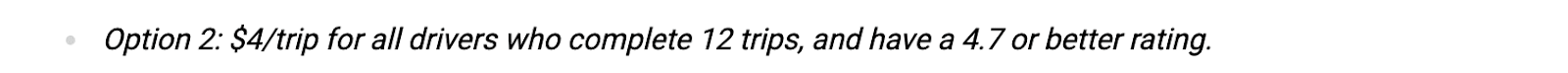
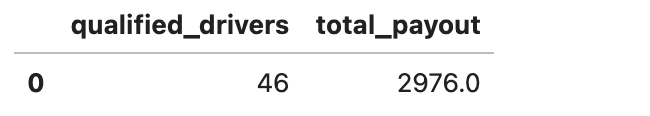


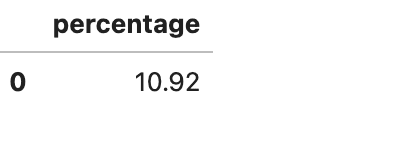
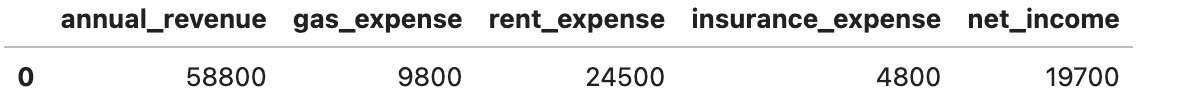

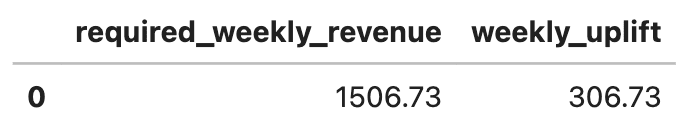

Image de l’auteur | Toile
La bibliothèque Pandas possède l’une des communautés à la croissance la plus rapide. Cette popularité a ouvert la porte à des alternatives, comme polaires. Dans cet article, nous explorerons une telle alternative, DuckDB.
DuckDB est une base de données SQL que vous pouvez exécuter directement dans votre cahier. Aucune configuration n’est nécessaire et aucun serveur n’est nécessaire. Il est facile à installer et peut fonctionner avec des pandas en parallèle.
Contrairement à d’autres bases de données SQL, vous n’avez pas besoin de configurer le serveur. Cela fonctionne simplement avec votre cahier après l’installation. Cela signifie pas de maux de tête de configuration locaux, vous écrivez instantanément le code. DuckDB Handles Filtrage, se joindre àet agrégations avec une syntaxe SQL propre, par rapport aux pandas, et fonctionne beaucoup mieux sur les grands ensembles de données.
Assez avec les termes, commençons!
Projet de données – Modélisation commerciale Uber
Nous l’utiliserons avec Jupyter Notebook, le combinant avec Python pour l’analyse des données. Pour rendre les choses plus excitantes, nous travaillerons sur un projet de données réel. Commençons!
Voici le lien Au projet de données, nous utiliserons dans cet article. Il s’agit d’un projet de données d’Uber appelé Modeling Business Modeling de Partner.
Uber a utilisé ce projet de données dans le processus de recrutement pour les positions de science des données, et il vous sera demandé d’analyser les données de deux scénarios différents.
- Scénario 1: Comparez le coût de deux programmes de bonus conçus pour mettre plus de conducteurs en ligne pendant une journée bien remplie.
- Scénario 2: Calculez et comparez le revenu net annuel d’un chauffeur de taxi traditionnel contre celui qui s’associe à Uber et achète une voiture.
Ensemble de données de chargement
Chargeons d’abord le dataframe. Cette étape sera nécessaire; Par conséquent, nous enregistrerons cet ensemble de données avec DuckDB dans les sections suivantes.
import pandas as pd
df = pd.read_csv("dataset_2.csv")
Exploration de l’ensemble de données
Voici les premières lignes:
Voyons toutes les colonnes.
Voici la sortie.
Connectez DuckDB et enregistrez le DataFrame
Bon, c’est un ensemble de données vraiment simple, mais comment pouvons-nous connecter DuckDB avec cet ensemble de données?
Tout d’abord, si vous ne l’avez pas encore installé, installez DuckDB.
La connexion avec DuckDB est facile. De plus, si vous souhaitez lire la documentation, vérifiez-la ici.
Maintenant, voici le code pour établir une connexion et enregistrer le DataFrame.
import duckdb
con = duckdb.connect()
con.register("my_data", df)
Bien, commençons à explorer sept requêtes qui vous feront économiser des heures de travail de pandas!
1. Filtrage multi-critères pour les règles d’admissibilité complexes
L’un des avantages les plus importants de SQL est la façon dont il gère naturellement le filtrage, en particulier le filtrage multi-conditions, très facilement.
Implémentation du filtrage multi-critère dans DuckDB vs Pandas
DuckDB vous permet d’appliquer plusieurs filtres à l’aide de SQL où les clauses et la logique, qui évolue bien à mesure que le nombre de filtres augmente.
SELECT
*
FROM data
WHERE condition_1
AND condition_2
AND condition_3
AND condition_4
Voyons maintenant comment nous écrivions la même logique en pandas. Dans les pandas, la petite logique est exprimée à l’aide de masques booléens chaînés avec des supports, qui peuvent être verbeux dans de nombreuses conditions.
filtered_df = df(
(df("condition_1")) &
(df("condition_2")) &
(df("condition_3")) &
(df("condition_4"))
)
Les deux méthodes sont également lisibles et applicables à une utilisation de base. DuckDB est plus naturel et plus propre car la logique devient plus complexe.
Filtrage multicritères pour le projet de données Uber
Dans ce cas, nous voulons trouver des conducteurs qui sont admissibles à un programme de bonus Uber spécifique.
Selon les règles, les conducteurs doivent:
- Être en ligne pendant au moins 8 heures
- Terminez au moins 10 voyages
- Acceptez au moins 90% des demandes de conduite
- Avoir une note de 4,7 ou plus
Maintenant, tout ce que nous avons à faire est d’écrire une requête qui fait tous ces filtrages. Voici le code.
SELECT
COUN(*) AS qualified_drivers,
COUNT(*) * 50 AS total_payout
FROM data
WHERE "Supply Hours" >= 8
AND CAST(REPLACE("Accept Rate", '%', '') AS DOUBLE) >= 90
AND "Trips Completed" >= 10
AND Rating >= 4.7
Mais pour exécuter ce code avec Python, nous devons ajouter des méthodes con.execute (« » « » « » « ) et fetchdf () comme indiqué ci-dessous:
con.execute("""
SELECT
COUNT(*) AS qualified_drivers,
COUNT(*) * 50 AS total_payout
FROM data
WHERE "Supply Hours" >= 8
AND CAST(REPLACE("Accept Rate", '%', '') AS DOUBLE) >= 90
AND "Trips Completed" >= 10
AND Rating >= 4.7
""").fetchdf()
Nous le ferons tout au long de l’article. Maintenant que vous savez comment l’exécuter dans un cahier Jupyter, nous ne montrerons que le code SQL à partir de maintenant, et vous saurez le convertir en version pythonique.
Bien. Maintenant, n’oubliez pas que le projet de données souhaite que nous calculons le paiement total de l’option 1.
Nous avons calculé la somme du conducteur, mais nous devons le multiplier par 50 $, car le paiement sera de 50 $ pour chaque conducteur, donc nous le ferons avec le décompte
* 50.
Voici la sortie.
Filtrage multicritères
2. Agrégation rapide pour estimer les incitations commerciales
SQL est idéal pour l’agrégation rapidement, surtout lorsque vous devez résumer les données entre les lignes.
Mise en œuvre de l’agrégation dans DuckDB vs Pandas
SELECT
COUNT(*) AS num_rows,
SUM(column_name) AS total_value
FROM data
WHERE some_conditionDuckDB vous permet d’agréger les valeurs entre les lignes en utilisant des fonctions SQL comme la somme et compter dans un bloc compact.
filtered = df(df("some_condition"))
num_rows = filtered.shape(0)
total_value = filtered("column_name").sum()Dans les pandas, vous devez d’abord filtrer le dataframe, puis compter séparément et résumer en utilisant des méthodes de chaînage.
DuckDB est plus concis et plus facile à lire et ne nécessite pas de gestion des variables intermédiaires.
Projet de données d’agrégation dans Uber
- Bon, passons au deuxième schéma de bonus, option 2. Selon la description du projet, les conducteurs recevront 4 $ par voyage si:
- Ils effectuent au moins 12 voyages.
Avoir une note de 4,7 ou mieux.
SELECT
COUNT(*) AS qualified_drivers,
SUM("Trips Completed") * 4 AS total_payout
FROM data
WHERE "Trips Completed" >= 12
AND Rating >= 4.7Cette fois, au lieu de simplement compter les chauffeurs, nous devons ajouter le nombre de voyages qu’ils ont achevés car le bonus est payé par voyage, pas par personne.
Le décompte nous indique combien de conducteurs se qualifient. Cependant, pour calculer le paiement total, nous calculerons leurs voyages et multiplions par 4 $, comme l’exige l’option 2.
Agrégation dans DuckDB
Voici la sortie.
Agrégation dans DuckDB
Avec DuckDB, nous n’avons pas besoin de traverser les lignes ou de construire des agrégations personnalisées. La fonction de somme s’occupe de tout ce dont nous avons besoin.
3. Détecter les chevauchements et les différences à l’aide de la logique booléenne
Dans SQL, vous pouvez facilement combiner les conditions en utilisant une logique booléenne, comme et, ou non.
Implémentation de la logique booléenne dans DuckDB vs Pandas
SELECT *
FROM data
WHERE condition_a
AND condition_b
AND NOT (condition_c)DuckDB prend en charge la logique booléenne nativement dans la clause WHERE Utilisation et, ou non.
filtered = df(
(df("condition_a")) &
(df("condition_b")) &
~(df("condition_c"))
)Les pandas nécessitent une combinaison d’opérateurs logiques avec des masques et des parenthèses, y compris l’utilisation de «~» pour la négation.
Bien que les deux soient fonctionnels, DuckDB est plus facile à raisonner sur le moment où la logique implique des exclusions ou des conditions imbriquées.
Boolean Logic for Uber Data Project
Maintenant, nous avons calculé l’option 1 et l’option 2, quelle est la prochaine étape? Il est maintenant temps de faire la comparaison. N’oubliez pas notre prochaine question.
Boolean Logic in Duckdb
SELECT COUNT(*) AS only_option1
FROM data
WHERE "Supply Hours" >= 8
AND CAST(REPLACE("Accept Rate", '%', '') AS DOUBLE) >= 90
AND "Trips Completed" >= 10
AND Rating >= 4.7
AND NOT ("Trips Completed" >= 12 AND Rating >= 4.7)C’est là que nous pouvons utiliser la logique booléenne. Nous utiliserons une combinaison de et et non.
Voici la sortie.
Boolean Logic in Duckdb
- Décomposons-le:
- Les quatre premières conditions sont là pour l’option 1.
La pièce Not (..) est utilisée pour exclure les conducteurs qui sont également admissibles à l’option 2.
C’est assez simple, non?
4. Dimensionnement de cohorte rapide avec filtres conditionnels
Parfois, vous voulez comprendre la taille d’un groupe ou d’une cohorte spécifique dans vos données.
Mise en œuvre de filtres conditionnels dans DuckDB vs Pandas?
SELECT
ROUND(100.0 * COUNT(*) / (SELECT COUNT(*) FROM data), 2) AS percentage
FROM data
WHERE condition_1
AND condition_2
AND condition_3DuckDB gère le filtrage de la cohorte et le calcul en pourcentage avec une requête SQL, incluant même des sous-requêtes.
filtered = df(
(df("condition_1")) &
(df("condition_2")) &
(df("condition_3"))
)
percentage = round(100.0 * len(filtered) / len(df), 2)Les pandas nécessitent le filtrage, le comptage et la division manuelle pour calculer les pourcentages.
DuckDB ici est plus propre et plus rapide. Il minimise le nombre d’étapes et évite le code répété.
COHORT SIDICE POUR UBER DES DONNÉS PROJET
- Maintenant, nous sommes à la dernière question du scénario 1. Dans cette question, Uber veut que nous découvrions les chauffeurs qui ne pouvaient pas réaliser certaines tâches, comme les voyages et le taux d’acceptation, mais avaient des notes plus élevées, en particulier les moteurs.
- Terminé moins de 10 voyages
- Avait un taux d’acceptation inférieur à 90
Avait une note supérieure à 4,7
SELECT
ROUND(100.0 * COUNT(*) / (SELECT COUNT(*) FROM data), 2) AS percentage
FROM data
WHERE "Trips Completed" < 10
AND CAST(REPLACE("Accept Rate", '%', '') AS DOUBLE) = 4.7Maintenant, ce sont trois filtres distincts, et nous voulons calculer le pourcentage de conducteurs satisfaisant chacun d’eux. Voyons la requête.
Voici la sortie.
Dimensionnement de cohorte dans DuckDB
Ici, nous avons filtré les lignes où les trois conditions ont été remplies, les avons comptées et les avons divisées par le nombre total de conducteurs pour obtenir un pourcentage.
5. Requêtes arithmétiques de base pour la modélisation des revenus
Maintenant, disons que vous voulez faire des mathématiques de base. Vous pouvez écrire des expressions directement dans votre instruction SELECT.
Implémentation de l’arithmétique dans DuckDB vs Pandas
SELECT
daily_income * work_days * weeks_per_year AS annual_revenue,
weekly_cost * weeks_per_year AS total_cost,
(daily_income * work_days * weeks_per_year) - (weekly_cost * weeks_per_year) AS net_income
FROM dataDuckDB permet à l’arithmétique d’être écrite directement dans la clause SELECT comme une calculatrice.
daily_income = 200
weeks_per_year = 49
work_days = 6
weekly_cost = 500
annual_revenue = daily_income * work_days * weeks_per_year
total_cost = weekly_cost * weeks_per_year
net_income = annual_revenue - total_costLes pandas nécessitent plusieurs calculs intermédiaires dans des variables distinctes pour le même résultat.
DuckDB simplifie la logique mathématique dans un bloc SQL lisible, tandis que les pandas deviennent un peu encombrés avec des affectations variables.
Projet de base de l’arithmétique dans Uber
Dans le scénario 2, Uber nous a demandé de calculer la quantité d’argent (après les dépenses) que le conducteur fait par an sans s’associer à Uber. Voici quelques dépenses comme le gaz, le loyer et l’assurance.
Arithmétique de base dans DuckDB
SELECT
200 * 6 * (52 - 3) AS annual_revenue,
200 * (52 - 3) AS gas_expense,
500 * (52 - 3) AS rent_expense,
400 * 12 AS insurance_expense,
(200 * 6 * (52 - 3))
- (200 * (52 - 3) + 500 * (52 - 3) + 400 * 12) AS net_incomeCalculons maintenant les revenus annuels et soustrayons les dépenses.
Voici la sortie.
Arithmétique de base dans DuckDB
Avec DuckDB, vous pouvez écrire ceci comme un bloc de matrice SQL. Vous n’avez pas besoin de Pandas DataFrames ou de boucle manuelle!
6. Calculs conditionnels pour la planification des dépenses dynamiques
Et si votre structure de coûts change en fonction de certaines conditions?
Mise en œuvre des calculs conditionnels dans DuckDB vs Pandas
SELECT
original_cost * 1.05 AS increased_cost,
original_cost * 0.8 AS discounted_cost,
0 AS removed_cost,
(original_cost * 1.05 + original_cost * 0.8) AS total_new_costDuckDB vous permet d’appliquer la logique conditionnelle à l’aide de réglages arithmétiques à l’intérieur de votre requête.
weeks_worked = 49
gas = 200
insurance = 400
gas_expense = gas * 1.05 * weeks_worked
insurance_expense = insurance * 0.8 * 12
rent_expense = 0
total = gas_expense + insurance_expensePandas utilise la même logique avec plusieurs lignes mathématiques et mises à jour manuelles sur les variables.
DuckDB transforme ce qui serait une logique en plusieurs étapes dans les pandas en une seule expression SQL.
Calculs conditionnels dans le projet de données Uber
- Dans ce scénario, nous modélisons maintenant ce qui se passe si le conducteur s’associe à Uber et achète une voiture. Les dépenses changent comme
- Le coût du gaz augmente de 5%
- L’assurance diminue de 20%
con.execute("""
SELECT
200 * 1.05 * 49 AS gas_expense,
400 * 0.8 * 12 AS insurance_expense,
0 AS rent_expense,
(200 * 1.05 * 49) + (400 * 0.8 * 12) AS total_expense
""").fetchdf()Plus de frais de loyer
Voici la sortie.
Calculs conditionnels dans DuckDB
7. Math des objectifs pour le ciblage des revenus
Parfois, votre analyse peut être motivée par un objectif commercial comme atteindre un objectif de revenus ou couvrir un coût unique.
Mise en œuvre des mathématiques axées sur les objectifs dans DuckDB vs Pandas DuckDB gère la logique en plusieurs étapes en utilisantCTES
WITH vars AS (
SELECT base_income, cost_1, cost_2, target_item
),
calc AS (
SELECT
base_income - (cost_1 + cost_2) AS current_profit,
cost_1 * 1.1 + cost_2 * 0.8 + target_item AS new_total_expense
FROM vars
),
final AS (
SELECT
current_profit + new_total_expense AS required_revenue,
required_revenue / 49 AS required_weekly_income
FROM calc
)
SELECT required_weekly_income FROM final. Il rend la requête modulaire et facile à lire.
weeks = 49
original_income = 200 * 6 * weeks
original_cost = (200 + 500) * weeks + 400 * 12
net_income = original_income - original_cost
# new expenses + car cost
new_gas = 200 * 1.05 * weeks
new_insurance = 400 * 0.8 * 12
car_cost = 40000
required_revenue = net_income + new_gas + new_insurance + car_cost
required_weekly_income = required_revenue / weeksLes pandas nécessitent la nidification des calculs et la réutilisation des variables antérieures pour éviter la duplication.
DuckDB vous permet de créer un pipeline logique étape par étape, sans encombrer votre cahier avec du code dispersé.
Projet de données de mathématiques axé sur les objectifs dans Uber
Maintenant que nous avons modélisé les nouveaux coûts, répondons à la question commerciale finale:
- Combien plus le conducteur doit gagner par semaine pour faire les deux?
- Rembourser une voiture de 40 000 $ dans un an
Maintenir le même revenu net annuel
WITH vars AS (
SELECT
52 AS total_weeks_per_year,
3 AS weeks_off,
6 AS days_per_week,
200 AS fare_per_day,
400 AS monthly_insurance,
200 AS gas_per_week,
500 AS vehicle_rent,
40000 AS car_cost
),
base AS (
SELECT
total_weeks_per_year,
weeks_off,
days_per_week,
fare_per_day,
monthly_insurance,
gas_per_week,
vehicle_rent,
car_cost,
total_weeks_per_year - weeks_off AS weeks_worked,
(fare_per_day * days_per_week * (total_weeks_per_year - weeks_off)) AS original_annual_revenue,
(gas_per_week * (total_weeks_per_year - weeks_off)) AS original_gas,
(vehicle_rent * (total_weeks_per_year - weeks_off)) AS original_rent,
(monthly_insurance * 12) AS original_insurance
FROM vars
),
compare AS (
SELECT *,
(original_gas + original_rent + original_insurance) AS original_total_expense,
(original_annual_revenue - (original_gas + original_rent + original_insurance)) AS original_net_income
FROM base
),
new_costs AS (
SELECT *,
gas_per_week * 1.05 * weeks_worked AS new_gas,
monthly_insurance * 0.8 * 12 AS new_insurance
FROM compare
),
final AS (
SELECT *,
new_gas + new_insurance + car_cost AS new_total_expense,
original_net_income + new_gas + new_insurance + car_cost AS required_revenue,
required_revenue / weeks_worked AS required_weekly_revenue,
original_annual_revenue / weeks_worked AS original_weekly_revenue
FROM new_costs
)
SELECT
ROUND(required_weekly_revenue, 2) AS required_weekly_revenue,
ROUND(required_weekly_revenue - original_weekly_revenue, 2) AS weekly_uplift
FROM finalÉcrivons maintenant le code représentant cette logique.
Voici la sortie.
Mathématiques axées sur les objectifs à DuckDB
Réflexions finales
Dans cet article, nous avons exploré comment se connecter avec DuckDB et analyser les données. Au lieu d’utiliser de longues fonctions de pandas, nous avons utilisé des requêtes SQL. Nous l’avons également fait en utilisant un projet de données réel que Uber a demandé dans le processus de recrutement des data scientists.
Pour les scientifiques des données travaillant sur des tâches lourdes de l’analyse, c’est une alternative légère mais puissante aux pandas. Essayez de l’utiliser sur votre prochain projet, surtout lorsque SQL Logic correspond mieux au problème.
Source link



